#AI 模型

Open-R1:DeepSeek-R1 的完全开源复现
Open-R1 是对 DeepSeek-R1 的完全开源复现,首次公开其强化学习(R1-Zero)与监督微调+RL(R1)双路径训练方法,涵盖数据构建、代码实现与超参细节。项目聚焦数学、编程与逻辑推理,旨在推动低成本、可复现的开源推理模型发展。

2025 年十大国外 AI 推理平台:LLM API 提供商对比
2025年十大国外AI推理平台出炉:Together AI以低成本高隐私见长,Fireworks AI主打多模态低延迟,OpenRouter支持300+模型统一调用,Groq依托LPU实现超低延迟,Hyperbolic提供80%成本降幅。覆盖性能、价格、合规与生态维度,助开发者精准匹配需求。

Meta 推出新的 AI 视频生成模型:VideoJAM,运动表现超越 Sora
Meta发布VideoJAM,专攻运动连贯性,动作自然度超越Sora。它联合学习画面与动作,通过Inner-Guidance机制动态优化生成方向,无需额外数据或模型改造,即可提升舞蹈、运动及慢动作等场景的真实感,兼容多种视频生成框架。

香港科技大学研发的开源音乐生成模型:YuE
香港科技大学开源音乐生成模型YuE,支持中英日韩四语,可依歌词生成最长5分钟、含主唱与伴奏的完整歌曲,强调结构连贯性与旋律表现力,为创作者提供Suno、Udio之外的新选择。
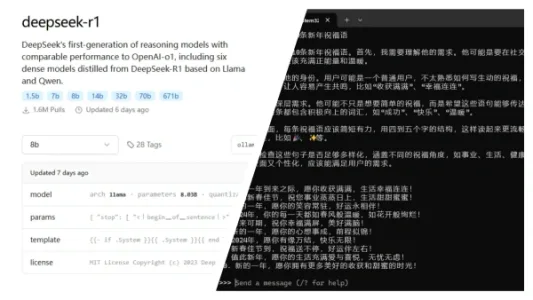
10分钟搞定!本地安装 DeepSeek-R1,全流程教程
DeepSeek-R1 国产开源大模型,推理能力媲美 OpenAI-o1。本文提供基于 Ollama 的本地安装全流程,适配 Windows/macOS/Linux,10–15 分钟即可离线运行。涵盖硬件要求、6 款模型(1.5B–70B)对比及一键启动命令,轻量设备也能低门槛体验高性能推理。

让 AI 成为科学家们改变科研方式的新力量
CSIRO AI科学总监Stefan Harrer指出,生成式AI正成为科学家的“超级助手”:实时追踪前沿、整合多源数据、加速蛋白质设计与药物研发——分析周期从数月缩至数天,新药研发时间减半。AI不替代人类,而是拓展认知边界,成为撬动科学突破的新支点。
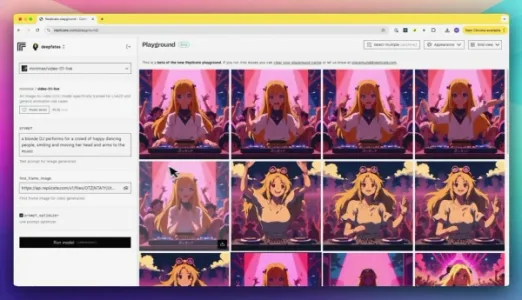
Replicate:按需付费使用 AI 模型的方案
Replicate 提供按需付费的 AI 模型调用服务,支持 Flux、海螺 AI、Llama、mmaudio 等多种生成式模型,可按 GPU 类型(如 H100 或 T4)计费,最低 $0.81/小时,适合低频使用或模型测试,比固定月费更灵活经济。

GPT-5 早已存在,而且已经在暗中影响着世界
有迹象表明,GPT-5可能已被OpenAI内部训练并用于模型蒸馏——类似Anthropic用未发布的Claude Opus 3.5提升Sonnet 3.6性能。这种“不发布、只内用”的策略,正推动大模型竞争从追求参数规模转向优化性价比与协同增益。
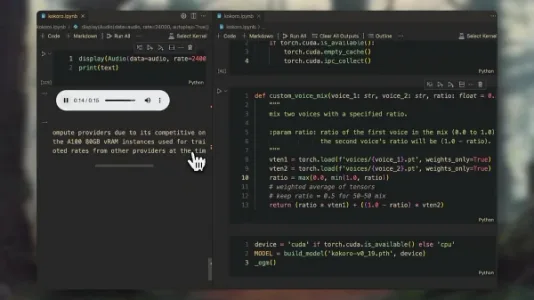
能够融合声音的小型 TTS(文本转语音)模型:Kokoro
Kokoro 是仅 82M 参数的轻量级 TTS 模型,支持从十种预设声线中任选两种,按任意比例混合生成个性化语音——如男女声 60:40 融合。提供简洁 API,访问 kokorotts.com 即可快速调用。