#视频生成

Meta 推出新的 AI 视频生成模型:VideoJAM,运动表现超越 Sora
Meta发布VideoJAM,专攻运动连贯性,动作自然度超越Sora。它联合学习画面与动作,通过Inner-Guidance机制动态优化生成方向,无需额外数据或模型改造,即可提升舞蹈、运动及慢动作等场景的真实感,兼容多种视频生成框架。

字节跳动推出新一代人像 AI 视频生成模型:OmniHuman-1
字节跳动推出OmniHuman-1人像视频生成模型,仅需单张人像图+音频/视频/混合信号即可驱动生成高保真动态视频。突破弱音频信号下生成瓶颈,支持任意比例输入与身体部位精准控制,适配唱歌、讲话、竖屏等多场景。

九大 AI 视频模型对比:林中白虎
AIGC达人Heather Cooper用“林中白虎”统一提示词,实测Google Veo 2、Sora、腾讯混元等九大AI视频模型。聚焦生成质量、镜头语言与氛围表现力,直观呈现当前文生视频技术的多强格局与差异化能力。
Krea.ai + DeepSeek AI 绘画视频生成新方式
Krea.ai 与 DeepSeek 深度融合,支持自然语言对话式操作,自动理解用户意图并生成高质量提示词,兼容 Flux、Ideogram、可灵、海螺等主流绘图与视频模型,零提示词基础也能高效创作。

Freepik 推出了基于 Flux Pro 的全新图像编辑一体化 AI 套件
Freepik 推出基于 Flux Pro 的一体化 AI 图像编辑套件,支持一键换脸、换装、智能调色等核心功能,并可联动可灵、海螺AI、Pika 等工具实现图像到视频的快速生成。年度会员低至每月 5.75 美元,适合需要高效视觉创作的设计师与内容创作者。
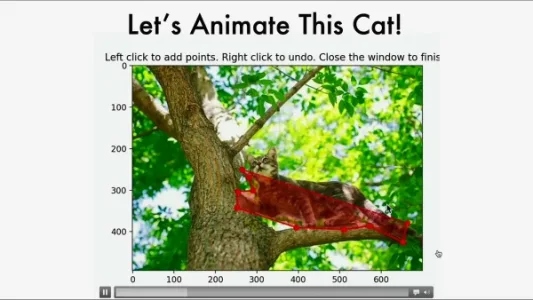
Netflix 精准动作控制 AI 视频模型:Go-with-the-Flow AI
Netflix推出Go-with-the-Flow AI模型,仅通过替换高斯噪声为“变形噪声”微调基础视频模型,即实现动作迁移、镜头控制、“剪切拖拽”动画、转台运动引导及文本/图像驱动的3D一致视频生成,全程零计算增量,支持I2V与T2V双路径。

Vidu 推出 2.0,可错峰无限生成视频
Vidu 2.0上线,专注图生视频,最快10秒成片,画面稳定性与角色一致性明显提升;标准年费用户每月8美元,非高峰时段可无限生成,性价比突出,成为可灵、海螺AI之外值得考虑的国产新选择。

AI 创意视频:角色三重奏
Nim 推出「角色三重奏」创意视频功能,融合 Flux 与 CogVideoX 模型,支持通过文生图+图生视频双提示词,批量生成含三种姿态、表情、动作及动态镜头的角色设定视频,适用于角色概念开发与动画预演。

如何使用 Runway 绘画模型 Frames
Runway 新推 AI 绘画模型 Frames,画面更逼真、风格控制更精准;操作类似 Midjourney,支持一键将生成图像转为视频,打通静态绘图到动态内容的创作链路。