#多模态
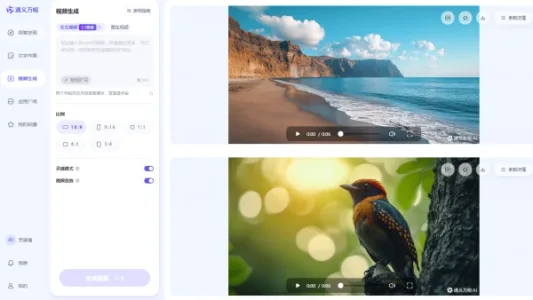
实测阿里通义万相的视频音效生成
实测阿里通义万相视频音效生成功能:开启后AI自动分析画面,匹配环境音效或背景音乐。海浪、小鸟、卡通吉他手视频音效较贴切,瓦力视频因主体识别不准仅获随机配乐。目前长于氛围营造,对具体主体音效的精准识别仍有提升空间。

Figure AI 兑现承诺,人形机器人 Figure 02 展示推理能力
Figure 02 展示真正自主推理能力:自研多模态AI可识别环境、理解陌生物体并自主决策放置位置,初步具备协作能力;虽当前动作较慢,但投资人预计其速度未来可达人类1.2–1.5倍,通用人形机器人正进入自学新阶段。

能够自主学习的 AI 通用人形机器人:Figure AI
Figure AI 推出新一代人形机器人 Figure 02,搭载自研多模态大模型与6摄像头AI视觉系统,支持实时对话、常识性视觉推理及自主学习;16关节机械手力量媲美人类,续航超20小时。已落地宝马工厂实操装配任务,并于今年2月终止与OpenAI合作,全面转向自研AI。

2025 年十大国外 AI 推理平台:LLM API 提供商对比
2025年十大国外AI推理平台出炉:Together AI以低成本高隐私见长,Fireworks AI主打多模态低延迟,OpenRouter支持300+模型统一调用,Groq依托LPU实现超低延迟,Hyperbolic提供80%成本降幅。覆盖性能、价格、合规与生态维度,助开发者精准匹配需求。

字节跳动推出新一代人像 AI 视频生成模型:OmniHuman-1
字节跳动推出OmniHuman-1人像视频生成模型,仅需单张人像图+音频/视频/混合信号即可驱动生成高保真动态视频。突破弱音频信号下生成瓶颈,支持任意比例输入与身体部位精准控制,适配唱歌、讲话、竖屏等多场景。

九大 AI 视频模型对比:林中白虎
AIGC达人Heather Cooper用“林中白虎”统一提示词,实测Google Veo 2、Sora、腾讯混元等九大AI视频模型。聚焦生成质量、镜头语言与氛围表现力,直观呈现当前文生视频技术的多强格局与差异化能力。
DeepSeek 发布开源多模态模型 Janus Pro 7b,可本地部署
DeepSeek 开源多模态模型 Janus Pro 7B,基于 DeepSeek V2 构建,支持图像理解与生成,训练数据超9000万样本(含7200万合成美学数据),采用自回归Transformer架构,集成文本编码器与图像解码器,可通过 Hugging Face 或 GitHub 免费获取,支持 FAST API 与 Gradio 本地部署。

免费开源的小型多模态模型:Molmo
艾伦研究所开源小型多模态模型Molmo,支持文本、图像、语音输入,具备“指向”交互能力,7B版本仅用百万级高质量图像训练,在视觉问答、文档理解等任务中表现优于GPT-4o,所有权重已开放下载。
字节跳动开源口型同步模型:LatentSync
字节跳动开源口型同步模型LatentSync,支持音频一键生成高自然度嘴型动画;融合Stable Diffusion提升画质,创新TREPA技术显著改善帧间连贯性,有效抑制嘴型跳变,效果媲美EMO、Vasa-1。