#多模态

Gemini 2.0:从聊天机器人到智能体的进化
Gemini 2.0 实现从对话到行动的跨越:原生支持自主调用搜索、代码解释器、地图等工具,完成多步协同任务;多模态能力更懂文化语境,可生成地域化图像与情境化语音;Flash 版性能反超前代 Pro;专注增强人类能力,为开发者提供构建实用智能体的新基座。

谷歌推出 Whisk:用图片和 AI 重新定义创意表达
谷歌实验室推出图片驱动AI工具Whisk,支持拖拽图片自动解构为“主题、场景、风格”三要素,并基于Gemini+Imagen 3重组生成全新创意图像。它不复制原图,而是提取视觉精髓,适合数字艺术、贴纸等快速创意探索。
第六天:ChatGPT 多模态视频交互功能
ChatGPT第六天正式向大众开放视频通话功能,支持实时音视频交互与多模态指导,例如通过手机摄像头手把手教用户冲泡咖啡。AI由此迈出从纯文本到“看得见、听得到、能指导”的关键一步,工作、学习与生活交互方式或将迎来实质性变化。
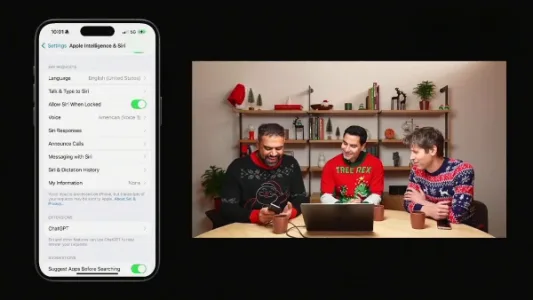
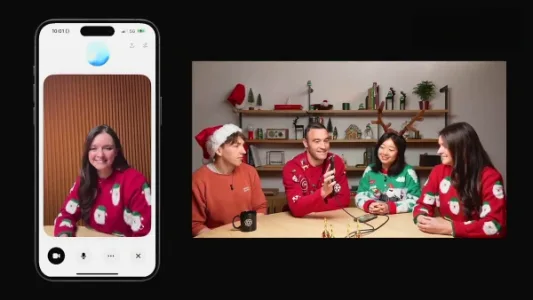
第五天:ChatGPT 正式登陆苹果全系设备
ChatGPT 正式登陆苹果全系设备,支持与 Siri 智能协同、写作全流程辅助(从策划到润色)、实时视觉理解(相机直连问答),Mac 端双击 Command 键即可唤起并分析当前文档。目前尚未向国内用户开放,但国产大模型深度集成有望加速落地。
Claude 开发电脑操控模型
Claude 3.5 Sonnet 已具备基础电脑操控能力,能通过屏幕截图识别界面、移动光标、点击和输入,模拟人类操作;在OSWorld评估中达14.9%,领先同类模型;目前处于公测阶段,安全等级为AI安全级别2,需警惕提示注入等风险。

一款将静态教科书中的图示转化为互动物理模拟的创做神器
这款工具用Segment Anything和多模态大模型,自动识别物理教科书中的静态图示,生成可嵌入页面的互动物理模拟,覆盖光学、电路、运动学等场景;结合教师反馈优化出实验增强、动画图示、双向互动与参数可视化四类策略,提升教学趣味性与个性化。

OpenAI 推出实时语音 API 公测版
OpenAI 推出实时语音 API 公测版,支持低延迟流式语音对话、中断响应与函数调用,集成六种自然声音;同步在 Chat Completions API 中新增音频输入输出能力。开发者可用单一接口构建多模态对话体验,适用于教育、客服、辅助功能等场景。

Meta 发布革命性 AR 眼镜原型 Orion
Meta发布AR眼镜原型Orion,70度超广视角、碳化硅镜片与微型LED投影集成于接近普通眼镜的轻量机身;搭载自研芯片及语音、眼动、手势与EMG腕带多模态交互,旨在构建无缝融合AI与现实的下一代计算平台。

字节跳动与浙大联合开发 Loopy 模型,性能媲美阿里微软
字节跳动与浙大联合推出Loopy语音驱动肖像模型,仅需单张图像+音频即可生成自然口型、微表情及头部运动,支持照片/动漫/雕塑等多种风格与侧脸输入;其创新时序模块能建模长程运动规律,无需手动设定运动模板,效果媲美阿里EMO与微软VASA。