#多模态
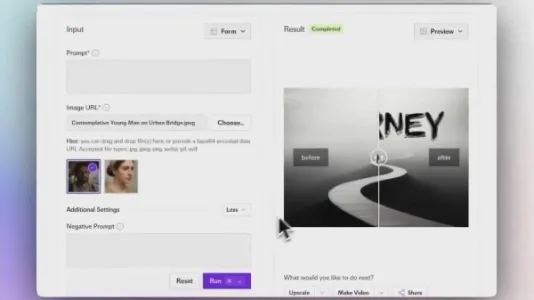
自然语言图像编辑工具 Step1X Edit 介绍
Stepfun开源自然语言图像编辑模型Step1X-Edit,支持用文本指令完成昼夜转换、加眼镜、添文字等精细编辑,效果接近GPT-4o与Gemini 2。基于多模态大模型与扩散解码器协同,需较高显存(512×512约42.5GB),推荐80GB GPU运行。

突破时长,无限长度开源 AI 视频生成模型:SkyReels-V2
SkyReels-V2 是首个支持无限长度视频生成的开源模型,首创 Diffusion Forcing 机制实现任意时长无缝续写;在 T2V/I2V 任务中综合性能达开源领先水平,指令遵循性与一致性显著优于同类模型,部分指标媲美 Runway、Kling 等商业系统。
微软发布万能 Office 文档转换 MCP 服务器:markitdown-mcp
微软推出 markitdown-mcp 工具,专注从 Office 文档、PDF、音视频、网页等数十种格式中提取语义化内容,输出结构清晰的 Markdown;不追求样式还原,专为大模型输入、文本分析与知识挖掘优化,支持 CLI、Python API、插件扩展及 Azure 文档智能集成。
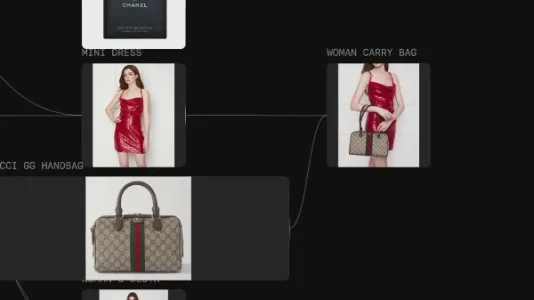
Flora 商品广告制作工作流
Flora 是一款画布式AI创意工具,支持文本→图像→视频端到端工作流编排,已集成 GPT-4o mini、Gemini 2.0、Flux Pro、Veo2、可灵2 等30+主流多模态模型,可保存复用工作流,助力专业设计师高效批量产出广告内容。
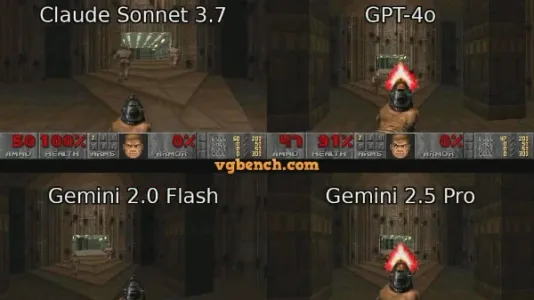
VideoGameBench: AI 模型游戏智能的基准测试
普林斯顿大学推出VideoGameBench基准,涵盖20款GB/MS-DOS经典游戏,专测视觉-语言模型在真实游戏环境中的理解、推理与操作能力;Lite版本支持暂停游戏以缓解响应延迟。实验表明,当前VLM在目标导向性、动作精度及机制理解上仍存在明显短板。

OpenAI 发布 o3 和 o4-mini,模型推理与多模态能力迈入全新阶段
OpenAI发布o3与o4-mini,首次将工具调用深度融入思维链,支持数百次自动多轮操作;在编程(SWE-bench最优)、科研、法律等垂直领域表现突出;强化多模态推理,可处理低质图像并调用Python工具;配套Codex CLI提升本地自动化能力,兼顾性能、成本与实用性。
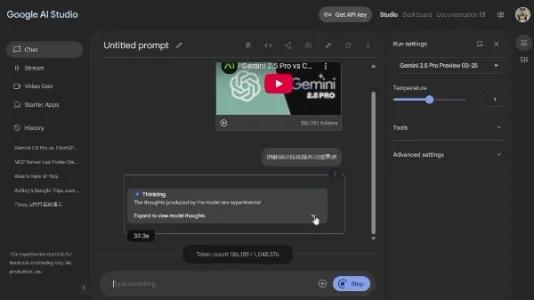
Google Gemini 2.5 Pro 新增对 YouTube 视频的直接支持
Gemini 2.5 Pro 新增 YouTube 视频直连能力,粘贴链接即可自动转录、翻译、生成摘要或改写文案;处理10分钟对话类视频约需2分钟、耗19万token,现于 Google AI Studio 免费开放使用。
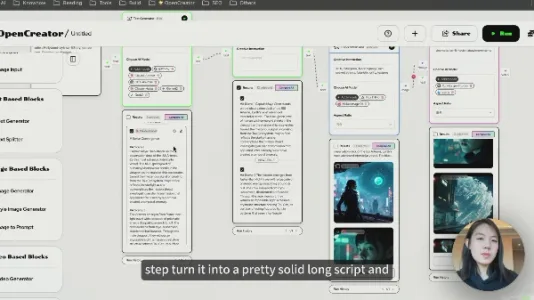
OpenCreator:重新定义 AI 创作工作流
OpenCreator 以模块化设计重构 AI 创作流,支持文本、图像、视频等任务自由连线组合,并行调用多模型实时对比效果;按量付费+免费积分机制降低试用门槛,让创作者按需搭建专属工作流,专注创意本身。

Llama 4 开源大模型家族:开启原生多模态 AI 创新的新时代
Meta开源Llama 4系列,含Scout(1000万Token上下文)、Maverick及训练中的Behemoth,原生支持文本、图像、视频多模态理解;采用MoE架构提升效率,多语言训练规模达Llama 3的10倍,安全与偏见控制显著优化。