#多模态

Google 搜索接入 Gemini 3 推出生成式 UI 功能
Google 将 Gemini 3 模型接入搜索 AI 模式,显著提升复杂问题理解与推理能力,并推出生成式 UI:支持动态视觉布局、实时生成交互工具(如三体模拟、贷款计算器)及多模态响应。目前面向美国 AI Pro/Ultra 用户开放,后续将逐步扩展。

Captain:突破 RAG 局限的新一代知识检索引擎
Captain 是一款由 YC 投资的新一代知识检索引擎,基准测试准确率达 95%,显著超越传统 RAG 的 78%;采用创新的无限上下文窗口架构,支持多模态数据与海量非结构化知识的高精度、低延迟检索,无需复杂调优即可无缝接入企业数据源。

DeepSeek 发布了一款超强的开源 OCR 模型:DeepSeek-OCR
DeepSeek 开源 OCR 模型 DeepSeek-OCR 提出“文本渲染为图”新范式,用自研视觉编码器将长文档高压缩为少量视觉 Token,10 倍压缩下还原精度达 97%;支持多语言、复杂版式与图表识别,端到端输出 Markdown/HTML,兼具高效推理与泛视觉理解能力。

AI Master 对 Gemini 3.0 的预测
据网传谷歌内部文件,Gemini 3.0 或将于10月下旬发布,主打更强逻辑推理与编程能力、原生智能体操作(如订票、发邮件)、深度整合 Workspace、多模态支持(文本/图/视频),并推出超快响应的 Flash 版及 Android 本地 Nano 模型,构建覆盖多场景的 AI 生态系统。
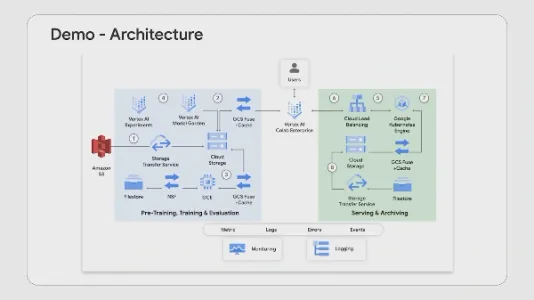
如何通过谷歌云为 AI 和机器学习设计存储方案
谷歌云通过Vertex AI与GCS构建AI/ML全链路存储方案:支持S3迁移、Filestore挂载保障Checkpoint、GCS Fuse与Anywhere Cache加速训练推理、实时资源监控及模型归档部署,兼顾性能、可靠性与运维效率。

ChatGPT 模型系列官方使用指南
OpenAI官方发布ChatGPT模型系列使用指南,详解GPT-4o、GPT-4.5、o4-mini等六款模型的适用场景与提示词范例:GPT-4o支持全模态日常任务;GPT-4.5强化情感表达与创意写作;o4-mini系列专注高效技术推理;o3和o1-pro分别面向复杂多步分析与高精度长周期任务。

π0.5:迈向开放世界泛化机器人的基础模型
π0.5是Physical Intelligence推出的视觉-语言-行动(VLA)基础模型,通过多源异质数据协同训练,显著提升机器人在全新家庭环境中的泛化能力。它能理解物理操作与任务语义,完成清洁、整理等复杂长程任务,仅需约100个训练环境即可接近定制化训练效果,降低对海量场景数据的依赖。
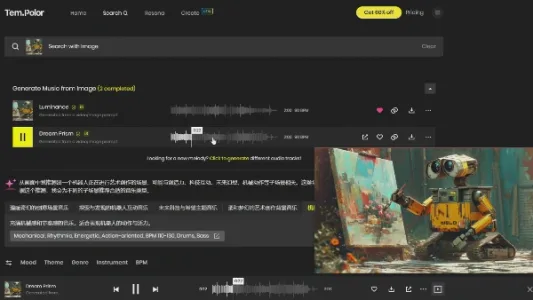
通过图片、视频生成音乐的 AI 神器:Tem.Polor
Tem.Polor 是一款视觉驱动的AI音乐生成工具,支持上传图片或视频,自动分析画面内容与情绪,生成风格契合的专属背景音乐。不同于Suno、Udio等文生音模型,它为短视频、图文等内容创作者提供了更直观、高效的配乐方案。

英伟达 "描述一切"(Describe Anything) 模型介绍
英伟达联合伯克利等机构推出“描述一切”(Describe Anything)模型,支持通过点选、框选、涂鸦等方式交互指定图像或视频局部区域,自动生成精准自然的语言描述。其核心DAM模型融合SAM等分割技术,实现“协同分割+语言理解”,突破整图描述局限,适用于医疗影像、自动驾驶、教育等需细粒度视觉理解的场景。