#多模态
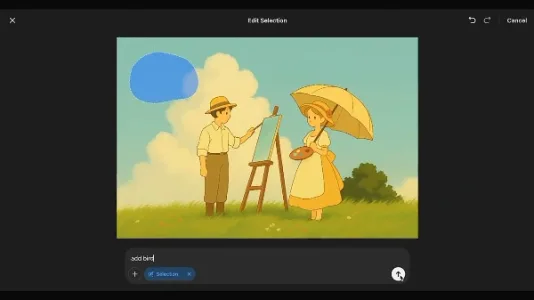
GPT-4o 真的成了 AI 图像编辑器
GPT-4o 不再只是对话模型,已具备图像生成、理解与交互式编辑能力,支持自然语言指令修改图片细节。其多模态“全能”特性正模糊AI工具与专业图像软件的边界,为设计师和普通用户提供更直觉的视觉创作方式。
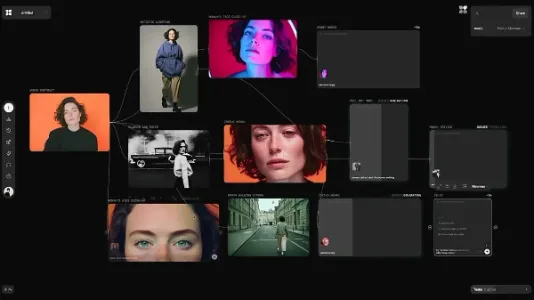
FLORA:专为创作者打造的智能画布,让创意一气呵成!
FLORA 是面向创作者的智能画布工具,整合多模态AI能力,支持从故事分析到视觉生成的一站式创意流程。内置黑白、棚拍灯光、电影感、X光、柔焦、极致细节、超写实等7种风格化选项,显著提升设计直观性与效率。
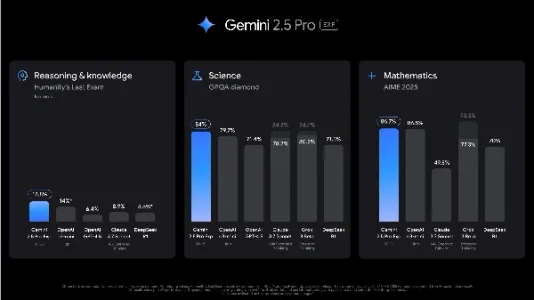
Google 推出 Gemini 2.5:最智能的 AI 模型!
Google发布Gemini 2.5,首次引入“思考能力”,可自主推理、优化决策;在GPQA、AIME 2025等高难度测试中领先,“人类终极考试”达18.8%;编程能力跃升,SWE-Bench得分63.8%,能一键生成完整p5js游戏;支持100万Token上下文与原生多模态理解。
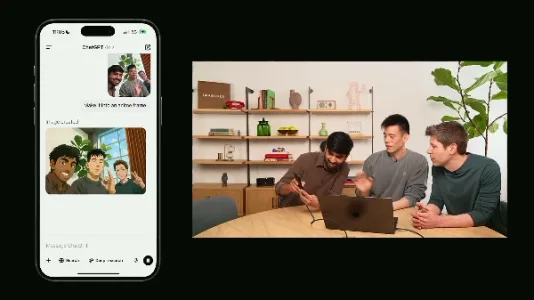
OpenAI 发布 GPT-4o 原生图像生成功能
OpenAI 为 GPT-4o 推出原生图像生成功能,成为继 Gemini、Grok 3 后第三款全能多模态模型。支持文生图、风格迁移、带准确文本的图像生成、教育漫画创作、个性化设计及多轮编辑,兼顾创作自由与实用性,图像质量优异,速度将持续优化。
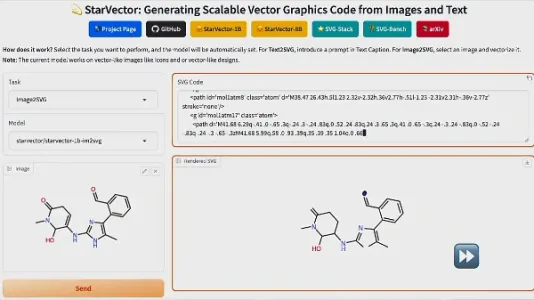
基于多模态大模型的 SVG 代码生成器:StarVector
StarVector 是一款多模态 SVG 代码生成器,支持图像或文本输入,直接生成语义清晰、结构紧凑的 SVG 代码。它不只拟合轮廓,而是理解图像内容与文本意图,实现 Image-to-SVG 和 Text-to-SVG 双向转换,适合设计师、前端开发者快速构建可缩放矢量图形。

SynCity:开创无需训练的 3D 世界生成新范式
SynCity 是牛津大学提出的一种无需训练的 3D 世界生成方法,通过协同调用预训练的 2D(Flux)与 3D(TRELLIS)模型,以逐块生成、跨维转换和迭代混合的方式,构建连贯可探索的 3D 环境。它绕开传统高成本训练流程,显著提升生成效率与通用性,适用于多样化文本驱动的场景构建。

Google AI Studio 上线了屏幕实时分享功能
Google AI Studio 新增屏幕实时分享功能,支持串流 Chrome 标签页,让 Gemini 实时“看见”页面内容并语音交互,适用于编程辅助等场景;英文语音识别流畅,中文识别偶有误判为日文的情况。

我们可以通过 Gemma 3 开发哪些本地 APP
Gemma 3 是 Google 新发布的开源多模态大模型,支持文本+图像输入、128k上下文及140+语言,1B–27B多尺寸适配不同硬件。4位量化后4B模型仅需2.6GB VRAM,可本地部署于CPU或边缘设备,适用于OCR、离线翻译、文档分析、视觉搜索与个性化学习等隐私敏感场景。
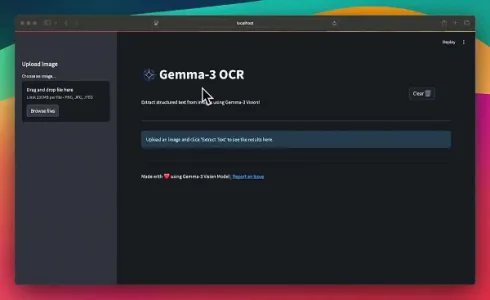
一款基于 Gemma 3 的开源 OCR 软件
基于 Gemma 3 12B 多模态模型的轻量级开源 OCR 工具,支持图像文本识别、翻译与答题等任务,显著降低多模态应用开发门槛。项目已开源,代码托管于 GitHub。