#图像生成
DeepSeek 发布开源多模态模型 Janus Pro 7b,可本地部署
DeepSeek 开源多模态模型 Janus Pro 7B,基于 DeepSeek V2 构建,支持图像理解与生成,训练数据超9000万样本(含7200万合成美学数据),采用自回归Transformer架构,集成文本编码器与图像解码器,可通过 Hugging Face 或 GitHub 免费获取,支持 FAST API 与 Gradio 本地部署。

AI 创意视频:角色三重奏
Nim 推出「角色三重奏」创意视频功能,融合 Flux 与 CogVideoX 模型,支持通过文生图+图生视频双提示词,批量生成含三种姿态、表情、动作及动态镜头的角色设定视频,适用于角色概念开发与动画预演。

如何使用 Runway 绘画模型 Frames
Runway 新推 AI 绘画模型 Frames,画面更逼真、风格控制更精准;操作类似 Midjourney,支持一键将生成图像转为视频,打通静态绘图到动态内容的创作链路。

Nvidia 推出文生图模型:Sana
Nvidia 推出轻量文生图模型 Sana,支持中文提示词,最高输出 4096×4096 图像;其 0.6B 小版本仅 Flux-12B 体积的 1/20,推理速度快超 100 倍,16GB GPU 上 1 秒即可生成 1024×1024 图像,适合本地高效部署。
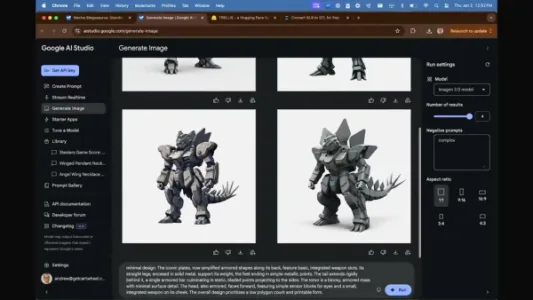
如何通过 Google AI Studio 快速制作手办
AIGC达人Andrew Carr用Google AI Studio免费工具链,几分钟内完成手办创作:Gemini 2.0 Flash生成概念与提示词,Imagen 3产出多角度参考图,Trellis转为GLB模型,再经ImageToStl导出STL文件,直接用于3D打印。

如何通过 Krea.ai 和 Sora 制作潮流广告
Krea.ai 新增图像训练功能,上传3张商品图即可生成专属LoRA模型;结合ChatGPT生成提示词与Sora视频生成,电商团队无需模特和实拍,就能高效产出高质量潮流广告图与视频,大幅降低制作成本。

如何通过 Pika 配料混合快速制作 3D 动漫
AIGC达人Techhalla分享用Pika“配料混合”快速生成3D动漫视频的工作流:先用Flux生成T-Pose角色与森林场景的参考图,再导入Pika结合提示词合成连贯动画,最后用剪映等工具完成剪辑配音——全程几分钟,角色与场景高度一致。
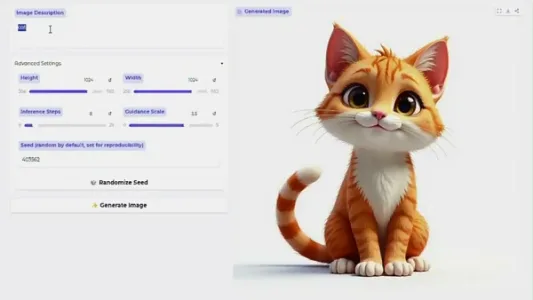
Text3D 一个用来制作高品质 3D 模型参考图像的 Gradio 应用
Text3D 是一款基于 Flux 模型的开源 Gradio 工具,无需本地部署,直接在 Hugging Face 上运行,可一键生成多角度、高细节的 3D 模型参考图,显著提升建模与纹理绘制效率,适合 3D 艺术师快速构思和验证设计。
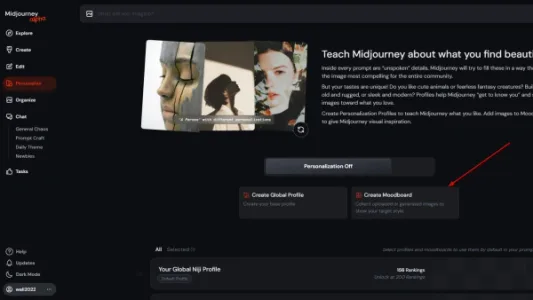
Midjourney 发布个性化风格模型架构新方法:情绪板
Midjourney 推出“情绪板”个性化风格架构,支持上传任意图片构建多组可命名风格配置;收敛速度提升至最高5倍,仅需40次评价即可起步,200次趋于稳定,大幅降低定制门槛。