#图像生成

谷歌发布全新视频与图像生成技术更新:Veo 2、Imagen 3 和 Whisk
谷歌推出Veo 2、Imagen 3与Whisk:Veo 2支持4K电影级视频生成,可精准控制镜头参数与胶片质感;Imagen 3显著提升图像细节与真实感;Whisk则为创意工作者提供新工具。三者协同强化AI在专业视觉创作中的可控性与表现力。

谷歌推出 Whisk:用图片和 AI 重新定义创意表达
谷歌实验室推出图片驱动AI工具Whisk,支持拖拽图片自动解构为“主题、场景、风格”三要素,并基于Gemini+Imagen 3重组生成全新创意图像。它不复制原图,而是提取视觉精髓,适合数字艺术、贴纸等快速创意探索。

Midjourney Patchwork 用户指南
Midjourney 推出 Patchwork 预览版——一个支持多人实时协作的无限 AI 画布,用于构建幻想世界。可拖拽缩放、生成角色与图像、链接碎片、设置风格参考,并支持权限管理与跨世界素材复用,目前正进行大规模并发压力测试。

xAI 绘画模型 Aurora 图片与提示词分享
xAI为Grok 2推出的图像生成器Aurora曾短暂上线,内容限制宽松,可生成公众人物及版权形象,但暴力内容过滤不足;擅长写实风格风景与静物,存在结构缺陷如缺手指、物体融合生硬。上线数小时后即被Flux替代。

ComfyUI 现已支持 Luma 绘画模型 Photon
ComfyUI 新增支持 Luma AI 的 Photon 绘画模型,通过安装「ComfyUI-LumaAI-API」插件即可调用。支持文生图、图像/角色/风格参考及图像修改等多类工作流,适用于微距摄影、矢量插图、华丽服饰设计、动物形态转换等创意场景。

Luma 发布绘画引擎 Photon 性能超越 Midjourney
Luma推出全新图像生成引擎Photon及极速版Photon Flash,在双盲测试中质量、创造力与理解力全面超越Midjourney等主流模型;1080p图像生成成本低至0.4美分,速度提升超10倍,专为电影、设计与艺术创作优化。
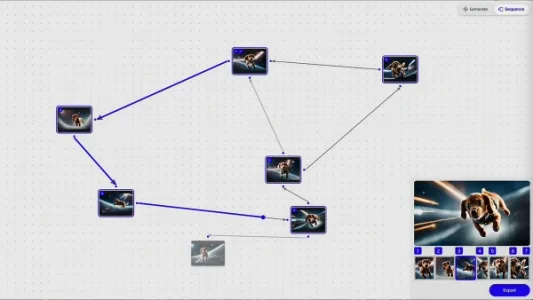
创造力即搜索:映射潜在空间
将创意过程视为在生成模型潜在空间中的搜索,新原型以图像节点与过渡视频构成图结构,支持非线性探索、变体生成与图生图等兼顾控制与偶然性的交互方式,配合开放工作空间和序列器,让AI真正成为创意探索的主动伙伴。
![FLUX1.1 [pro] 推出 Ultra 模式,能够生成400万像素的图像](https://img.caprompt.com/news/covers/thumbnail/news-cover-763-629ecb0651.webp)
FLUX1.1 [pro] 推出 Ultra 模式,能够生成400万像素的图像
FLUX1.1 [pro] 新增 Ultra 模式,支持 400 万像素高分辨率图像生成,单张仅需 10 秒,速度超同类模型 2.5 倍,成本低至 0.06 美元;同步上线 Raw 模式,显著提升人像多样性与自然摄影真实感;现开放 Replicate 平台调用。

Stable Diffusion 3.5 发布 ControlNets
Stable Diffusion 3.5 Large 新增 Blur、Canny、Depth 三款免费 ControlNets,支持 ComfyUI;Blur 可超分至 16K,Canny 精准控结构,Depth 助力建筑渲染与构图控制;ELO 测评用户偏好第一;年收入百万美元以下企业可免费商用。