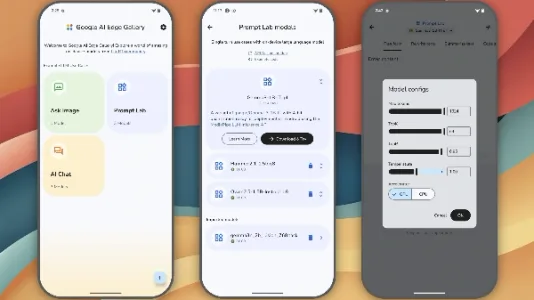
Google 推出 Android 本地模型运行神器:AI Edge Gallery
Google 推出实验性应用 AI Edge Gallery,支持在 Android 设备本地离线运行 Gemma 等生成式 AI 模型。无需联网即可实现图片问答、多轮对话、提示词实验,并可实时对比不同模型性能,还支持自定义 LiteRT 模型测试与 Hugging Face 一键集成。
AlphaEvolve:用进化方法推动算法创新的新一代自动化工具
AlphaEvolve 是 Google DeepMind 推出的 Gemini 驱动进化式编程工具,融合多模态大模型、自动化评估与进化算法,可自动生成、验证并优化算法代码。已在数据中心调度、TPU 硬件设计、FlashAttention 加速及复数矩阵乘法等场景实现突破,显著提升效率与性能,并推动算法创新范式变革。
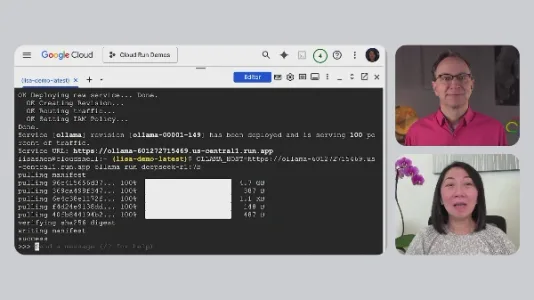
如何通过 Cloud Run 一键部署 DeepSeek
Google Cloud 工程师演示了用 Cloud Run 三步部署 DeepSeek 的方法:支持 GPU 实例、自动扩缩容(可缩至零),模型可按需加载或预置进镜像。无需运维底层资源,开发者能快速上线大模型服务,兼顾弹性、成本与易用性。
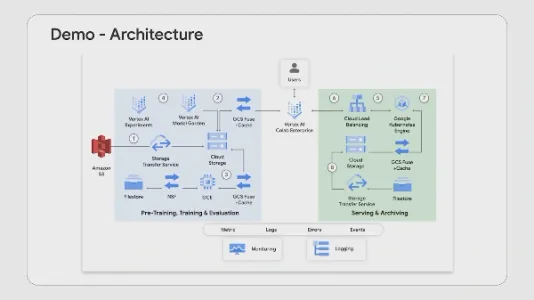
如何通过谷歌云为 AI 和机器学习设计存储方案
谷歌云通过Vertex AI与GCS构建AI/ML全链路存储方案:支持S3迁移、Filestore挂载保障Checkpoint、GCS Fuse与Anywhere Cache加速训练推理、实时资源监控及模型归档部署,兼顾性能、可靠性与运维效率。

AI 和科学发现的未来,DeepMind 创始人哈萨比斯访谈
哈萨比斯在剑桥访谈中指出,AI正重塑科学发现范式:AlphaFold已成百万科研人员标配工具;跨学科融合、直觉与实证结合、类“现代贝尔实验室”的灵活组织,是突破关键;技术发展需同步推进伦理规范与全球协作。

谷歌发布 Agent2Agent 协议(A2A),实现智能体互动操作
谷歌发布开源Agent2Agent(A2A)协议,为异构AI智能体提供统一通信标准,支持跨厂商、跨框架协作,具备安全认证、长任务处理与多模态能力;通过“Agent Card”实现动态能力发现,已获超50家技术及咨询公司支持。
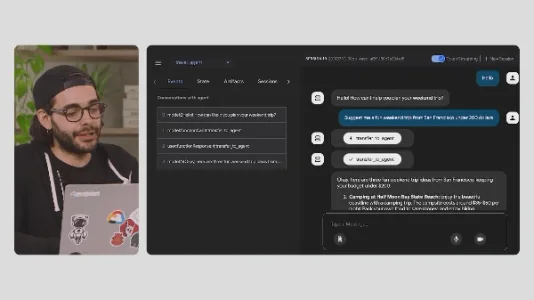
Google 推出开源智能体开发工具包:ADK( Agent Development Kit)
Google 开源智能体开发工具包 ADK,让构建智能体如写函数般简单。支持 Gemini 等任意大模型,兼容本地与云端部署,原生集成音视频流和 UI 沙盒调试。百行代码即可实现多智能体旅行规划应用,推动智能体开发标准化与落地。
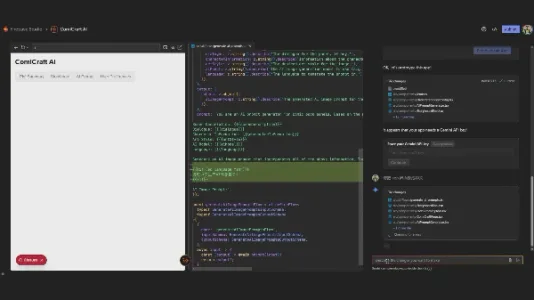
Google 发布全栈 AI 编程工具 Firebase Studio
Google 推出 Firebase Studio,一款集成 Gemini 的全栈 AI 编程工具,支持自然语言/线框图/截图生成应用原型,可导入多源代码库并用 Nix 定制环境。实测能快速生成 TypeScript + React 项目,虽界面简陋但支持 Gemini 实时迭代优化,提供免费浏览器端开发方案。
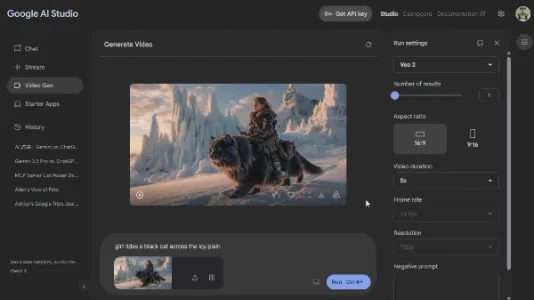
Google AI Studio 可免费制作 Veo 2 视频啦!
Google AI Studio 现免费开放 Veo 2 视频生成功能,支持文生视频与图生视频,可选横屏(16:9)或竖屏(9:16)格式,最快1分钟生成一段8秒高清视频,无需订阅即可体验。