
Google Labs 副总裁 Josh Woodward 聊 AI 视频的未来
Google Labs副总裁Josh Woodward提出“AI摄像机”构想:它不是拍摄工具,而是能对成片中任意元素(如角色服饰颜色)进行全局实时修改的创作系统,将大幅降低影视制作门槛,重塑从创作到后期的全流程。
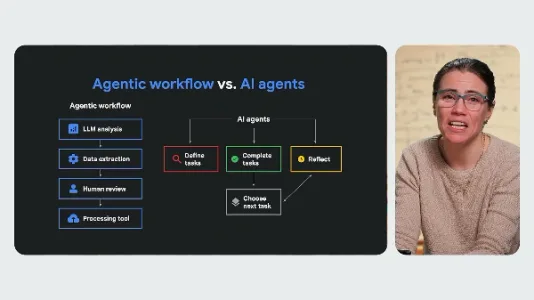
智能体还是智能体工作流
智能体强调大模型驱动的自主决策与非确定性执行,适合复杂灵活任务;智能体工作流则将AI能力嵌入预设流程,强调确定性、可控性与人工干预,更适配需稳定输出的业务场景。二者本质是自主性与可控性的权衡。

Gemini Robotics:让 AI 走入现实世界
Google DeepMind推出基于Gemini 2.0的两款具身智能模型:Gemini Robotics具备视觉-语言-行动能力,可直接控制ALOHA 2、Franka及人形机器人“阿波罗”;Gemini Robotics-ER强化空间理解与具身推理,任务成功率提升2–3倍,并引入分层安全机制与ASIMOV安全评估数据集。

Google 发布轻量级开源大模型:Gemma 3,让手机也能跑动大模型
Google发布开源大模型Gemma 3,含1B至27B多版本,其中1B版可在手机端流畅运行;原生支持140+语言及文本、图像、视频多模态输入,上下文窗口达12.8万Token;兼容Transformers、JAX等主流框架,继承Gemini 2.0核心技术,兼顾性能与终端部署效率。

Meta 计划推出独立 Meta AI 应用,全力竞争 ChatGPT 赛道
Meta将于2025年第二季度推出独立Meta AI应用,摆脱社交平台限制,支持跨设备交互;目标年底成为全球使用量最高的AI聊天工具,并可能推出类似ChatGPT Plus的付费订阅服务。

Google 量子计算机,5分钟完成超级计算机10万亿亿亿年的运算
谷歌发布105量子比特芯片Willow,5分钟完成超算需10万亿亿亿年(远超宇宙年龄)的运算,量子纠错取得关键突破;预计五年内将在药物研发、材料科学等领域实现传统计算无法达成的实际应用。
Google 创意AI绘画工具 Whisk 全面开放了
Google创意AI绘画工具Whisk全面开放,无需文字提示,上传图片即可融合主题、场景与风格生成原创图像;基于Imagen 3模型,支持灵感激发、智能推荐与编辑,适合设计师、插画师及创意爱好者快速产出视觉内容。

Veo 2 遵循摄影测量技术,使得 3D 摄像机跟踪成为可能
Google Veo 2生成的视频符合摄影测量原理,可精准提取3D摄像机运动数据,让安卓机器人、樱花场景等虚拟元素自然融入AI视频,无需改造现有特效工作流,为影视后期提供即插即用的AI协作新路径。

Google AI 课堂:智能体从概念到实践
Google AI 课堂指出,智能体无需严苛定义,而应关注“代理性程度”——即调用工具(LLM或硬编码)自主完成任务的能力。它可单点执行(如邮件助手),也能多体协同(如写作+审查组合)。Firebase Genkit、Playbook等开源工具已支持快速构建,适用从简单自动化到复杂场景的各类需求。