#DeepSeek
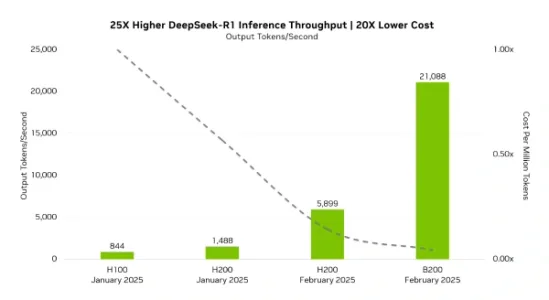
DeepSeek-R1 让 Blackwell 架构的性能大升级
英伟达推出TensorRT优化的FP4版DeepSeek-R1,运行于Blackwell架构时相较H100提升25倍收益、降低单Token成本20倍;MMLU测试达FP8版本99.8%精度,兼顾速度与准确率;FP4模型已开源至Hugging Face。

Grok 3 vs DeepSeek:AI 竞赛中的新对决
xAI发布Grok 3,计算资源提升10倍,支持128K上下文与输出,在数学、代码等任务上超越DeepSeek;后者以开源、低成本(费用仅为Grok 3约3%)和高定制性见长。二者分别代表闭源高性能与开源普惠两条技术路径。
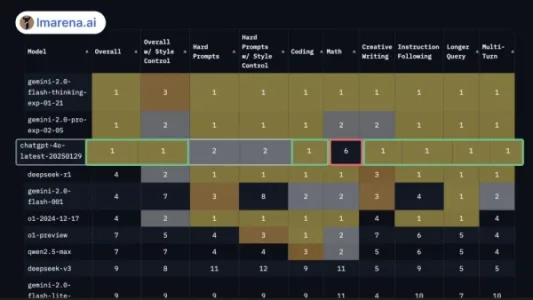
2025 Lmarena AI 模型基准测试最新排名
LMArena AI最新基准测试显示,Google Gemini 2.0两款模型综合表现居首,DeepSeek R1紧随其后;WebDev Arena编码竞赛中,Claude 3.5 Sonnet夺冠,DeepSeek R1与o3-mini-high分列二、三位。平台支持免费对话与众包投票评估。
Jina.ai 结合 DeepSeek 打造的智能搜索工具 Deep Search
Jina.ai 联合 DeepSeek 推出 Deep Search,基于思维链技术提供更精准、简洁的搜索结果。普通用户可免费网页搜索,开发者可通过低成本 API($0.02/百万 Token)快速集成 AI 搜索能力。

DeepSeek 小说创作提示词模板
DeepSeek小说创作提示词模板含12个结构化指令,覆盖从主题构思、角色塑造、章节写作到润色校对、读者反馈模拟及市场推广全流程,帮助创作者系统化完成高质量小说创作与出版准备。

从 V0 到 R1,deepseek 如何追平 GPT-4
DeepSeek 两年内从2023年V0迭代至2025年R1,在数学、逻辑与编程能力上追平GPT-4;通过MoE、MLA等架构创新,参数达6710亿,并以跨架构蒸馏技术实现高性能轻量部署,标志AI研发正转向“能力驱动”。

混合专家模型:AI 界的专家会诊制如何让大模型更高效?
混合专家(MoE)架构让大模型像“专家会诊”:通过门控机制动态调用不同子网络处理输入,训练中自然形成专长。Mixtral用8个专家超越GPT-3.5,DeepSeek R1总参6710亿但仅激活370亿,显著降本增效。

什么是大语言模型 LLM 蒸馏?
LLM蒸馏是将大模型(教师)通过概率分布输出的知识迁移至小模型(学生)的技术,由Hinton团队2015年提出。它能在大幅压缩参数量与资源占用的同时,保留97%左右的性能,如DistilBERT体积降40%、速度升60%。DeepSeek R1已推出1.5B–70B多档蒸馏版,支持低配设备本地部署。

DeepSeek R1 是如何炼成的
DeepSeek R1 经历V1至R1 Zero四阶段迭代,融合强化学习与监督微调,采用MoE架构提升效率;仅用2048块H800 GPU即逼近OpenAI顶级模型性能,显著降低训练与推理成本,推动高效透明AI推理落地。