LMArena AI,前身是lmsys.org,是由加州大学伯克利分校SkyLab 和 LMSYS 研究团队开发的 AI 模型评估平台。它专注于通过众包 AI 基准测试来评估 AI,用户可以在此平台上免费与AI聊天并进行投票,比较和测试不同的 AI 聊天机器人的性能。
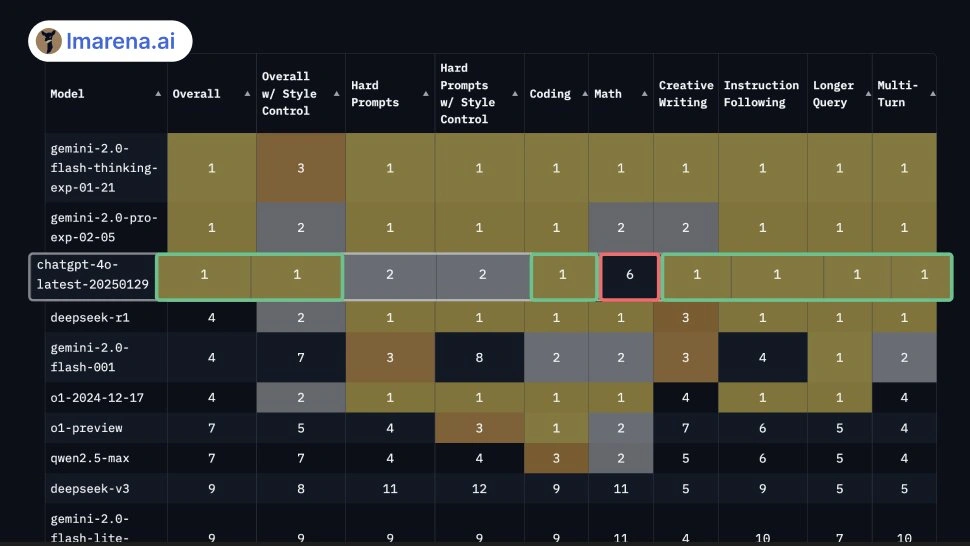
在最新的 LMArena AI 的各项基准测试中,Google Gemini 2.0 的两款模型获得了最好的成绩, DeepSeek R1 表现也相当不俗。ChatGPT-4o 近期也悄悄进行了升级,在很多方面都有所提升。
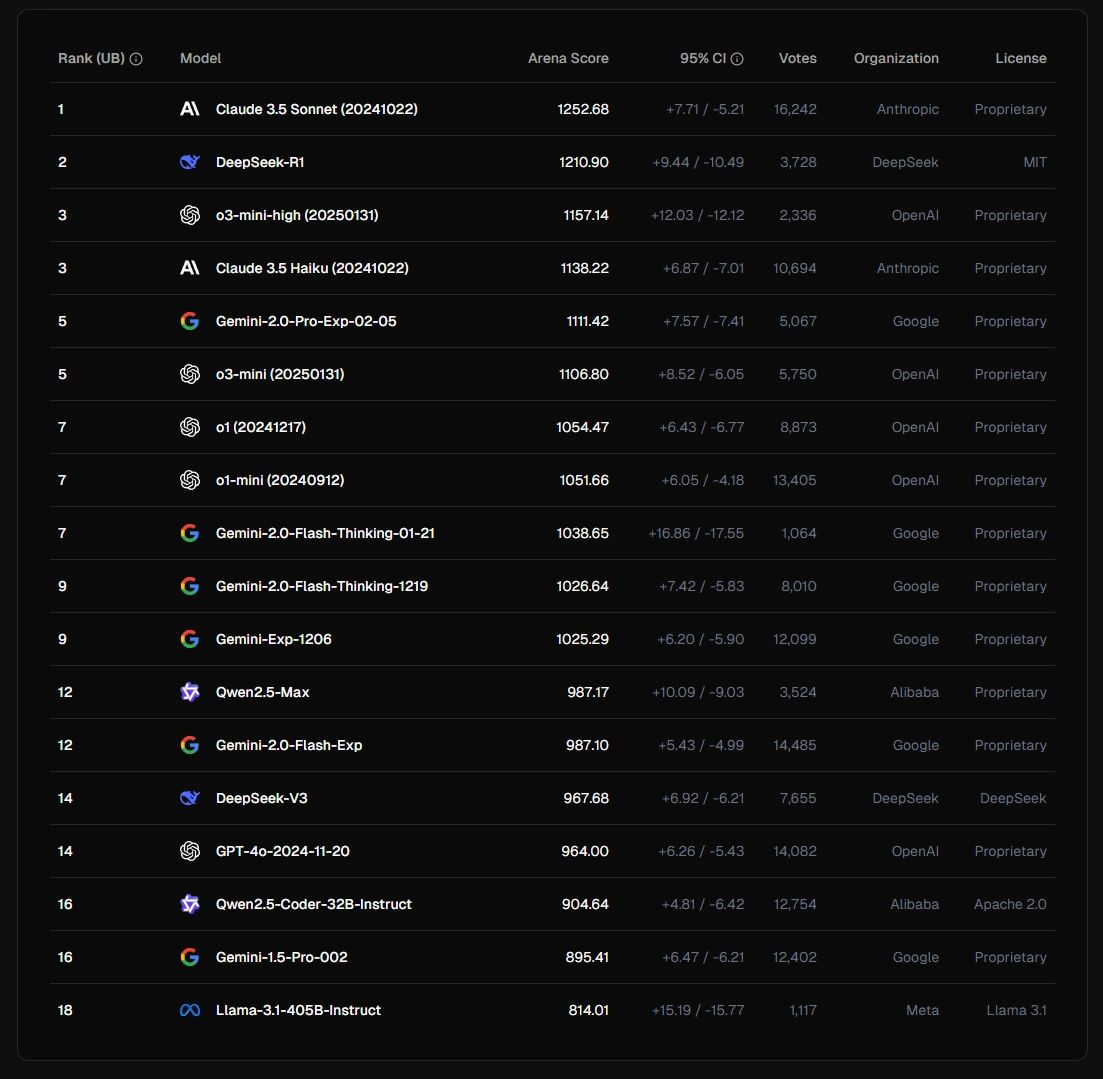
在最新 LMArena 的实时 AI 编码竞赛 WebDev Arena 中,Claude 3.5 Sonnet 仍处于第一,DeepSeek R1 暂居第二,o3-mini-high 名列第三。


