
英伟达表示,DeepSeek-R1 让 Blackwell 架构的性能大升级!相比四周前的 NVIDIA H100,不仅能带来 25 倍的收益提升,每个 Token 的成本还降低了 20 倍,性价比拉满![威武]
这一切都得益于 TensorRT DeepSeek 的优化,尤其是 FP4 计算,在保持超高精度的同时,在 MMLU 通用智能测试 中达到了 FP8 版本 99.8% 的得分,可谓既快又准!
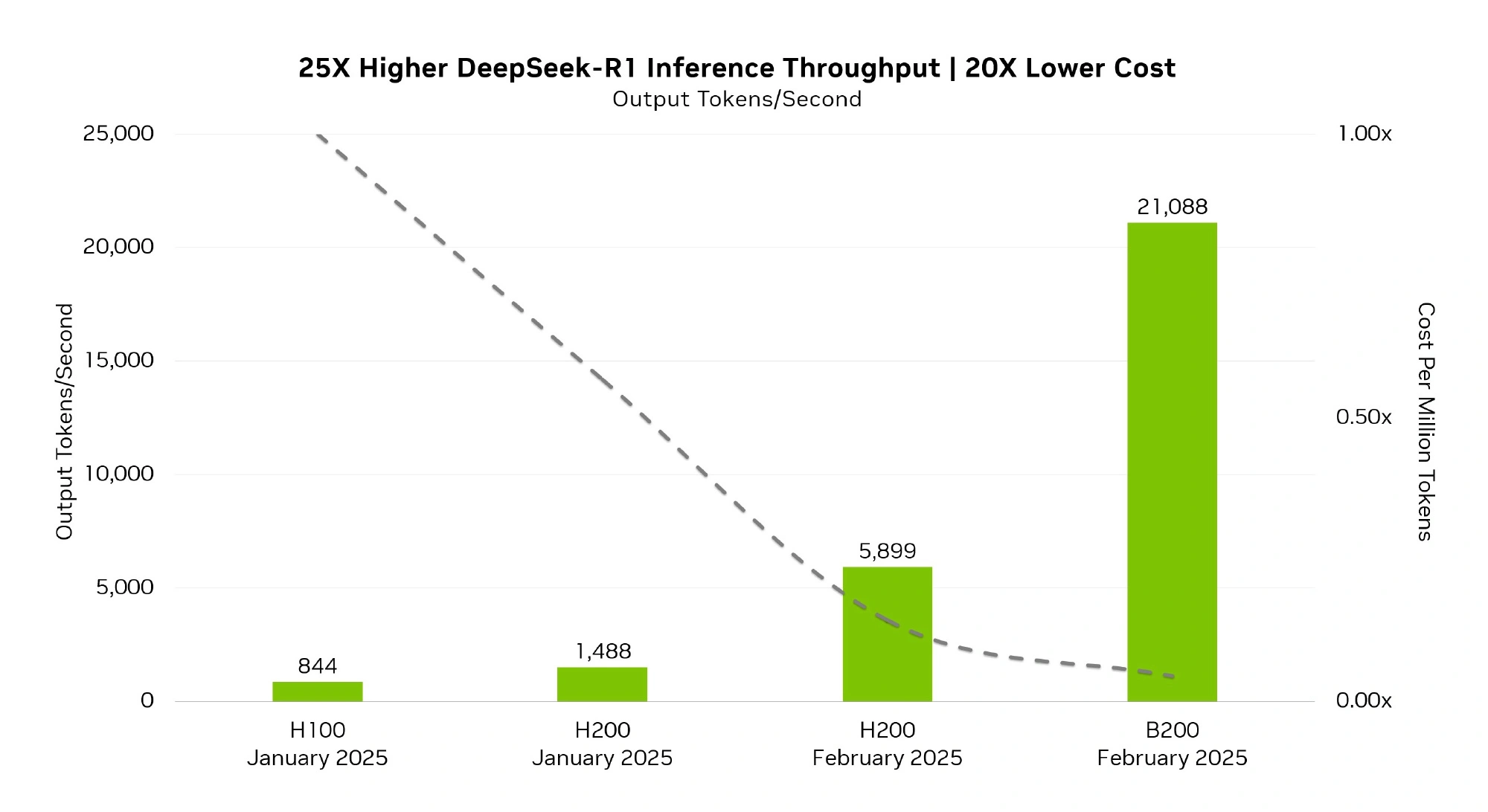
现在,FP4 优化版 DeepSeek checkpoint 已正式上线 Huggface。
英伟达表示,DeepSeek-R1 让 Blackwell 架构的性能大升级!相比四周前的 NVIDIA H100,不仅能带来 25 倍的收益提升,每个 Token 的成本还降低了 20 倍,性价比拉满![威武]
这一切都得益于 TensorRT DeepSeek 的优化,尤其是 FP4 计算,在保持超高精度的同时,在 MMLU 通用智能测试 中达到了 FP8 版本 99.8% 的得分,可谓既快又准!
现在,FP4 优化版 DeepSeek checkpoint 已正式上线 Huggface。

OpenAI 旗下 GPT-5.6 Sol Ultra 通过 64 路并行 agent 在 1 小时内生成了图论 CDC 猜想的证明文本,成本不足 500 美元。该成果引发争议,因缺乏 Lean 机械化验证、未公开完整推理轨迹及受限于图论形式化库不成熟,数学界对其有效性存疑。此事表明 LLM 已具备启发式数学搜索能力,但验证基础设施滞后仍是瓶颈。未来“多路并行+防放弃 prompt”或成范式,而完善 Lean 工具链是确立 AI 证明可信度的关键。

针对复杂疾病治疗难题,Arc 研究所正利用 AI 构建通用“虚拟细胞”模型。该模型将 RNA 表达视为生命语言,计划四年内通过 CRISPR 和单细胞测序完成 10 亿次实验进行训练。研究人员可借此在电脑模拟中预测基因或化学干预方案,实现从盲目猜测到精准预测的转变。该工具将于今年晚些时候开源,有望在未来四五年内推动个性化医疗及复杂疾病治疗取得临床突破。
OpenAI 正式发布 GPT-5.6,推出 Sol、Terra、Luna 三档模型。Sol 在 Agent 评测中领先,但编码基准落后竞品且存在 token 过度消耗问题,Terra 性价比显著提升。新功能包括程序化工具调用、缓存优化及 Sol 自主训练 Luna。尽管安全围栏较严且知识截止日期存疑,该版本仍属扎实迭代。对于 Codex 用户建议升级,而 Claude Code 用户需权衡工作流兼容性,两大 AI 厂商竞争已趋白热化。
围绕《DeepSeek-R1 让 Blackwell 架构的性能大升级》展开交流,未登录用户可浏览评论,登录后可参与讨论。