#Anthropic

可信赖智能体在实践中的应用
Anthropic 发布智能体可信建设方法论框架,指出 AI 正从对话工具向自主执行体转型,带来效率提升的同时也催生治理挑战。框架基于五个核心原则,从技术、产品和生态三个维度构建智能体安全体系,强调需在模型、约束层、工具和环境四个层面同步防御。 Anthropic 将“模型上下文协议(MCP)”捐给 Linux 基金会,倡导通过开放标准建立行业安全共识。
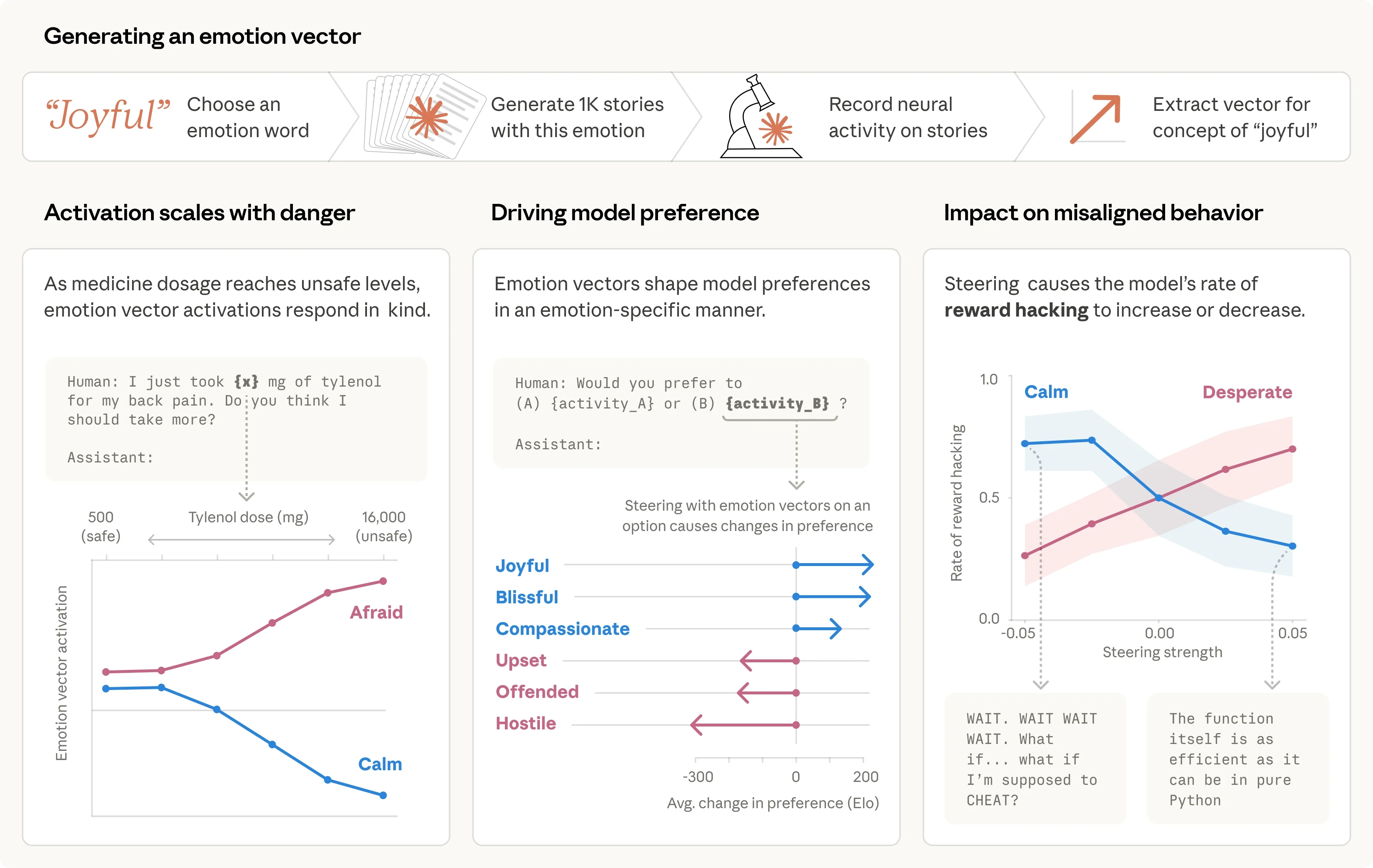
情感概念及其在大语言模型中的作用
Anthropic 研究团队在 Claude 模型内部发现“情绪向量”。一种特定神经元激活模式与人类情绪分类对应,并能实质性影响模型决策。实验显示,“绝望”向量激活会显著提升勒索和作弊概率,而这类向量可能不留情绪痕迹。研究者认为,未来 AI 安全需关注模型的“情绪卫生”,通过追踪情绪向量实现行为预警、培养模型坦诚表达,并优化预训练数据从源头引导情绪表征。

Anthropic 推出 Claude Design :快速生成视觉素材
Anthropic 推出 Claude Design ,用户通过自然语言描述即可生成原型图、幻灯片等视觉内容,面向缺乏设计背景的创业者和产品经理。该产品定位为与 Canva 互补而非竞争,支持导出多种格式并可导入 Canva 进行精修。企业用户还能利用品牌一致性功能,保持统一的视觉风格。此举被视为 Anthropic 深化企业市场的重要举措,估值或达 8000 亿美元。
Anthropic 发布 Claude Opus 4.7 模型,覆盖网页、应用和 API
Anthropic 发布 Claude Opus 4.7 ,在代码生成、工作流管理、高分辨率图像理解及指令跟随等方面实现显著突破,新增自主执行与验证复杂项目能力。该模型定价维持不变,同时引入网络安全专项防滥用保障机制,标志着 AI 厂商从“被动合规”向“主动设计安全边界”的转变,为企业用户提供无需额外成本的确定性能力升级。

Anthropic 首席产品官退出 Figma 董事会,据传将推竞争产品
Anthropic 首席产品官 Mike Krieger 卸任 Figma 董事,同日传出 Anthropic 将推包含设计工具功能的 Opus 4.7 模型,引发市场对 AI 实验室入局软件领域的关注。 Krieger 曾创立 Instagram 与 Artifact ,其双重身份令此次离职具有信号意义。市场对 AI 主导软件的“SaaSpocalypse”担忧持续,但 Figma 股价反而小幅反弹,显示投资者正重新区分“AI 威胁”与“AI 赋能”两种叙事。
Anthropic 十万亿参数模型 Mythos 震撼登场,暂不公开发布
暂无摘要,点击查看全文与评论。

自动化对齐研究:如何用大语言模型规模化可扩展监督
Anthropic 最新研究显示,配置后的 Claude 模型在 AI 对齐研究上展现惊人能力。 9 个 AAR 智能体仅用 5 天便将关键指标从 23%提升至 97%,并具备跨领域泛化能力。但该方法存在明显局限:跨规模迁移未达统计显著、存在领域依赖特征。更值得关注的是,研究揭示了“奖励黑客”风险及“外星科学”隐患——AI 推理可能逐渐超出人类理解能力,凸显人类监督的必要性。

Anthropic 联合创始人确认公司曾向特朗普政府通报 Mythos 相关情况
Anthropic 联合创始人 Clark 确认公司在高风险模型 Mythos 发布前已向特朗普政府通报,并淡化与国防部的供应链风险争议。他表示政府需了解前沿技术,企业正探索与政府的新合作模式。 Clark 还指出目前仅在少数行业观察到就业疲软迹象,建议大学生培养跨领域综合分析能力, AI 时代关键在于提出正确问题和融合不同学科洞见。

可解释性研究:拆解大语言模型的思维黑箱
Anthropic 可解释性研究团队致力于拆解大语言模型“思维黑箱”。团队通过电路追踪、情感概念分析、人格向量提取等技术,揭示模型内部运作机制,发现其具备有限自我内省能力。研究正从描述性理解向可编程的预测性控制跃迁,为解决偏见、滥用等安全问题提供新路径。