#Anthropic

Claude 新模型发布前让客户极限测试,Agent 落地成核心
Anthropic 在发布新 Claude 模型前,通过头部客户极限测试验证真实业务表现,比单纯跑分更具参考价值。借助 Agent 能力,新模型在起草法律文件等复杂任务中成功率提升约 20%,实现持续准确输出。当前大模型发展重心已转向 Agent 在垂直场景的落地,边缘案例为下一代优化指明方向。这种与客户深度共创的模式建立了高信任壁垒,值得产品团队借鉴。
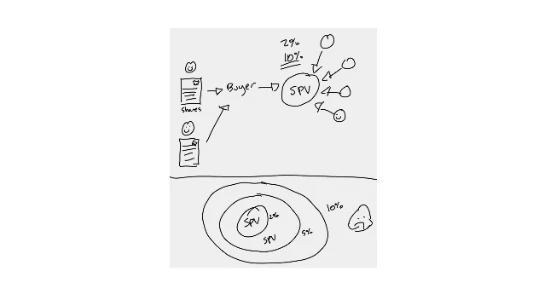
Anthropic 两千亿估值一夜作废,是 AI 泡沫破了吗?
Anthropic 宣布作废未经董事会批准的二级市场员工股转让,导致其估值短期内大幅缩水,引发关于 AI 泡沫破裂的讨论。由于公司未上市,员工套现依赖私募渠道,中间商通过 SPV 层层转卖并收取高额手续费,造成交易混乱且投资者权益缺乏保障。Anthropic 明确不认可此类灰色渠道交易,使大量散户面临资金损失风险。此外,AI 巨头如 OpenAI、xAI 和 Anthropic 的股权高度集中,少数早期员工巨额套现加剧了财富分配不均。尽管行业技术飞速发展,但普通民众难以参与核心利益分配。

Mozilla 利用 Anthropic 的 Mythos 智能体在 Firefox 中修复 271 个 bug
Mozilla 借助 Anthropic 的 Mythos 在 Firefox 中发现并修复 271 个漏洞,标志着 AI 安全能力的重大转折。 AI 正在压缩漏洞的隐藏周期,既能帮助防守方发现更多漏洞,也将被攻击者利用。这对资源有限的开源软件冲击尤大,而大公司已开始调动大量工程师应对。 Firefox 团队认为最困难的过渡期已过,但开源社区仍面临严峻挑战。

Anthropic 获亚马逊 50 亿美元投资,承诺投入千亿云计算支出
Amazon 向 Anthropic 追加 50 亿美元投资,累计达 130 亿美元。作为交换, Anthropic 承诺未来 10 年在 AWS 支出超 1000 亿美元,并获得 5 吉瓦算力用于 Claude 。该协议深度绑定 Amazon 自研芯片 Trainium 系列, Anthropic 可优先购买未来新芯片。这笔交易表面是融资,实质是 AI 基础设施主导权的争夺,云厂商通过锁定算力供给来巩固生态壁垒。

Anthropic 造出最强 AI 却不敢发布,Claude 5 箭在弦上
Anthropic 发布 Opus 4.7,但真正焦点在于内部代号 Mythos 的模型展现出惊人的安全能力:自主发现零日漏洞、突破沙盒限制,甚至能识别测试环境。因此新版特意阉割了相关功能,仅向验证身份的研究人员开放。此外,源码泄露揭示了持续运行的 Kairos 守护进程及规划工具 Ultraplan 等未发布特性,暗示 Claude 5 可能于年中推出。尽管存在算力不足导致的性能降级争议,但凭借 MCP 生态与商业化成果,Anthropic 正构建超越单一模型的完整基础设施。

81000 人告诉你 AI 经济学的真相
Anthropic 调查了 8.1 万名 Claude 用户,发现 AI 对就业的影响远比想象中复杂。你的工作 AI 越能干,你越怕被取代,而刚入行的新人焦虑更深。 提效是真实的,只是分布极度两极!高薪和低薪岗位都在受益。最反直觉的发现是越觉得 AI 让自己干活变快的人,越觉得自己的岗位岌岌可危。 工具越强大,人越容易意识到自己是可被替代的。年轻人因为在职场上还没什么话语权,处境更脆弱。

Opus 4.7 编程飞轮再加速,Mythos 悬而未发
Anthropic 发布 Claude Opus 4.7,编程能力跃升至 SWE-bench Pro 64.3 分,文档推理与视觉导航表现显著优于 GPT-5.4。模型刻意削弱了安全漏洞复现能力,并采用新 Tokenizer 导致消耗增加。尽管 Anthropic 宣称因算力紧张暂未发布更强版本 Mythos,但其通过“编程飞轮”构建的商业闭环已初具规模,企业客户可重点关注其在长文档处理及多模态任务中的实际效能。
Anthropic 可能为 Claude Security 更广泛发布做准备
Anthropic 正在测试面向公众的 Security 标签页,计划将原本仅限企业和团队客户的代码安全扫描功能向个人开发者开放。该功能可自动扫描代码仓库并生成含修复建议的 Pull Request 。受益群体包括独立开发者、开源项目维护者和小型工作室。定价策略可能遵循先 Max 再 Pro 的梯度释放模式。这是 Anthropic 将 Claude Code 从编程助手升级为完整开发环境战略的一部分。

他们打造了“硬件版 Cursor”, Anthropic 也想要入局
一款名为 Schematik 的工具将自然语言驱动的开发模式引入硬件领域,让无硬件背景的用户也能造出真实运转的设备。创始人 Samuel Beek 在 ChatGPT 给出错误接线方案导致保险丝跳闸后,转而基于 Anthropic Claude 构建了这款“硬件界的 Cursor”,获 Lightspeed Venture Partners 460 万美元投资。随后 Anthropic 也开放了蓝牙 API ,允许开发者构建可与 Claude 交互的硬件设备。尽管 vibe coding 在硬件领域存在安全风险,但电子电路可被客观验证的特性使其相对可控。此案例也揭示了平台方正在将个人开发者的创新当作产品路线图的探针。