#AI 模型

半监督学习:AI训练的成本优化之道
半监督学习用少量标注数据+大量未标注数据训练AI,显著降低人工标注成本。通过伪标签、聚类、主动学习等技术,模型能自主挖掘数据规律,提升泛化能力、缓解过拟合,更接近人类“观察—归纳”的学习方式。

从 ANI 到 AGI:超级对齐如何守护人类未来
AI正从狭义智能(ANI)加速迈向通用(AGI)乃至超级智能(ASI),随之而来的“超级对齐”难题日益紧迫:如何确保远超人类的系统始终服从人类价值观?现有方法如RLHF已显乏力,RLAF、迭代放大等新路径仍在探索中;这不仅是技术挑战,更倒逼人类厘清伦理共识。

扩散型大语言模型:文本生成范式的重大突破
Inception Labs推出首个生产级扩散型大语言模型Mercury,突破自回归范式,采用“从粗到细”迭代生成,推理快10倍、成本降10倍;支持全局优化与任意顺序编辑,在代码生成中耗时仅为传统模型的1/6。

Stability AI 与 Arm 强强联手,让手机也跑得动 AI
Stability AI 与 Arm 合作,首次实现 Stable Audio Open 模型在手机端本地运行,仅靠 Arm CPU 即可秒级生成高质量音频,速度提升30倍。无需联网、不传数据,兼顾隐私、便携与实时创作,为视频、音乐、播客等创作者提供口袋里的音频工作室。

从数据科学到 AI,职业生涯的重要抉择
AI岗位激增(2025年1月达5000个),偏爱Python、云平台、深度学习与NLP技能,但数据科学家的评估能力、业务理解等优势可平滑迁移。不必急于转岗,更宜在现有工作中融合AI工具与思维,找准适配路径。
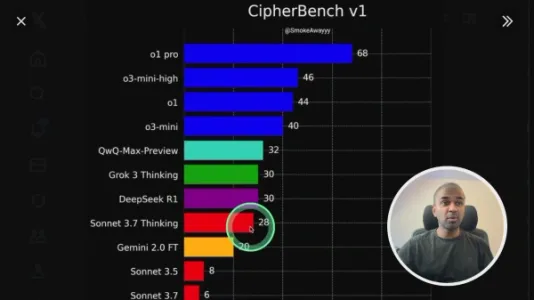
阿里巴巴通义千问 QwQ Max 推理能力超越 Claude 3.7
阿里通义千问QwQ Max预览版在CipherBench推理测试中超越Claude 3.7,与Grok 3、DeepSeek R1相当;AIME 2025数学题一次通过率达60%。采用Apache 2.0完全开源,支持多模态、工具调用,已免费上线Qwen Chat。

OpenAI 推出 GPT-4.5:更强大、更智能、更贴近人类的 AI 模型
OpenAI发布GPT-4.5研究预览版,在无监督学习上大幅突破:SimpleQA准确率达62.5%,幻觉率降至37.1%,显著优于GPT-4o与o3-mini;情感理解更细腻,创意与知识整合能力更强,交互更自然可信。
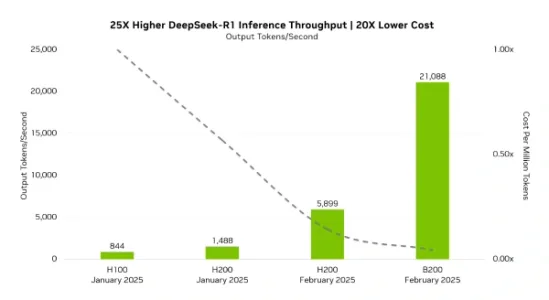
DeepSeek-R1 让 Blackwell 架构的性能大升级
英伟达推出TensorRT优化的FP4版DeepSeek-R1,运行于Blackwell架构时相较H100提升25倍收益、降低单Token成本20倍;MMLU测试达FP8版本99.8%精度,兼顾速度与准确率;FP4模型已开源至Hugging Face。

2025 年 12 款优秀的大语言模型
2025年12款主流大语言模型全景梳理:涵盖GPT-4o、Gemini、Claude、Llama、Mistral等,突出多模态、开源、轻量部署、强推理等差异化能力,兼顾技术特点与实际应用,反映当前LLM生态的多样性与演进方向。