
Runway Gen-4 图生视频入门教程
Runway Gen-4 图生视频教程上线,操作逻辑延续前代,上手门槛低;新增视频扩展、口型同步、风格转换与4K增强等功能,显著提升生成质量与创作灵活性,适合希望快速产出高质量短视频的创作者。

反思:智能体工作流中的关键优化机制
反思机制让智能体在生成答案后进行自我评估,识别逻辑漏洞与不确定性,实现“二次思考”以提升准确性。它特别适用于数学求解、代码验证等高精度任务,模拟人类复盘思维,但需权衡计算成本,并非所有场景必需。

揭开 AI 思维的黑盒:从神经科学视角理解人工智能
Anthropic 首次用神经科学方法观测到 Claude 在写诗前主动规划押韵与语义关联,证实其存在内部逻辑回路,而非仅靠统计匹配;这一突破为提升 AI 安全性、理解智能本质提供了新路径。

模型本地部署神器:Ollama
Ollama 是一款开源大模型本地部署工具,支持 Mistral、Llama、Gemma 等主流模型在普通笔记本上高效运行。通过量化优化与 LoRA 微调,兼顾性能、隐私与易用性,让开发者和普通用户无需依赖云服务即可离线使用大模型。
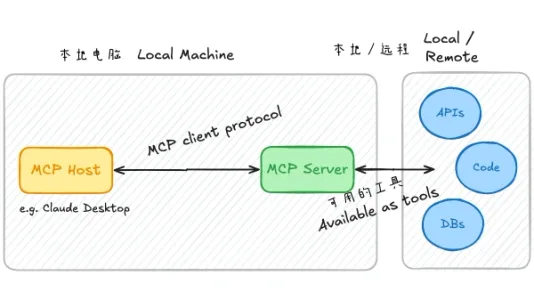
用 TypeScript 在 10 分钟内构建你的第一个 MCP 服务器
手把手教你用 TypeScript 10 分钟搭建首个 MCP 服务器,支持对接 Claude Desktop、Zed 等主流主机;涵盖项目初始化、SDK 集成、工具定义与调试全流程,让 AI 智能体轻松连接数据库、API 等数据源。

提高你的 3D 工作流效率:如何在 Blender 中设置 Tripo 并与 Cursor 同步
本文手把手教你将 Tripo AI 插件接入 Blender,并通过 MCP 服务器与 Cursor 编辑器联动,实现建模指令自动生成、重复任务自动化和跨工具协作,显著提升 3D 工作流效率,适合希望用 AI 加速创作的设计师与开发者。

LLM 量化:在性能与效率之间寻找平衡
LLM量化通过将参数压缩至16/8/4/2位整数,大幅降低存储与计算开销,让大模型得以在手机、笔记本等普通设备本地运行,兼顾效率与隐私。但精度下降是主要代价,GPTQ、AWQ等新技术正尝试在速度与准确率间找到更好平衡。
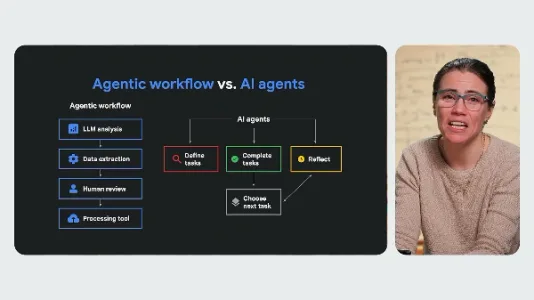
智能体还是智能体工作流
智能体强调大模型驱动的自主决策与非确定性执行,适合复杂灵活任务;智能体工作流则将AI能力嵌入预设流程,强调确定性、可控性与人工干预,更适配需稳定输出的业务场景。二者本质是自主性与可控性的权衡。
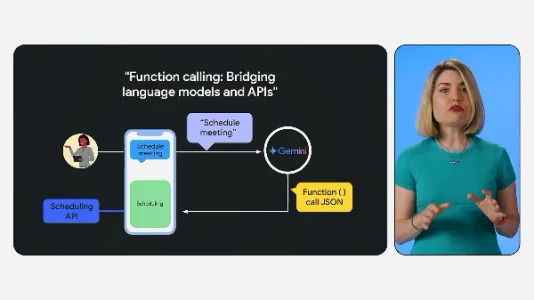
Gemini API 函数调用:连接 AI 与现实世界的桥梁
Gemini API 函数调用让模型能将自然语言(如“预订下周二下午3点会议室”)自动转为结构化指令,调用外部API执行真实任务;开发者只需预定义函数声明,执行由后端完成,支持多轮对话与灵活扩展,是大模型连接现实工具的关键能力。