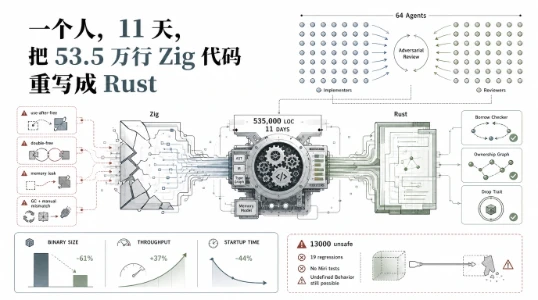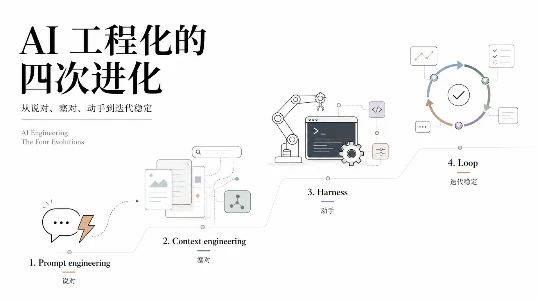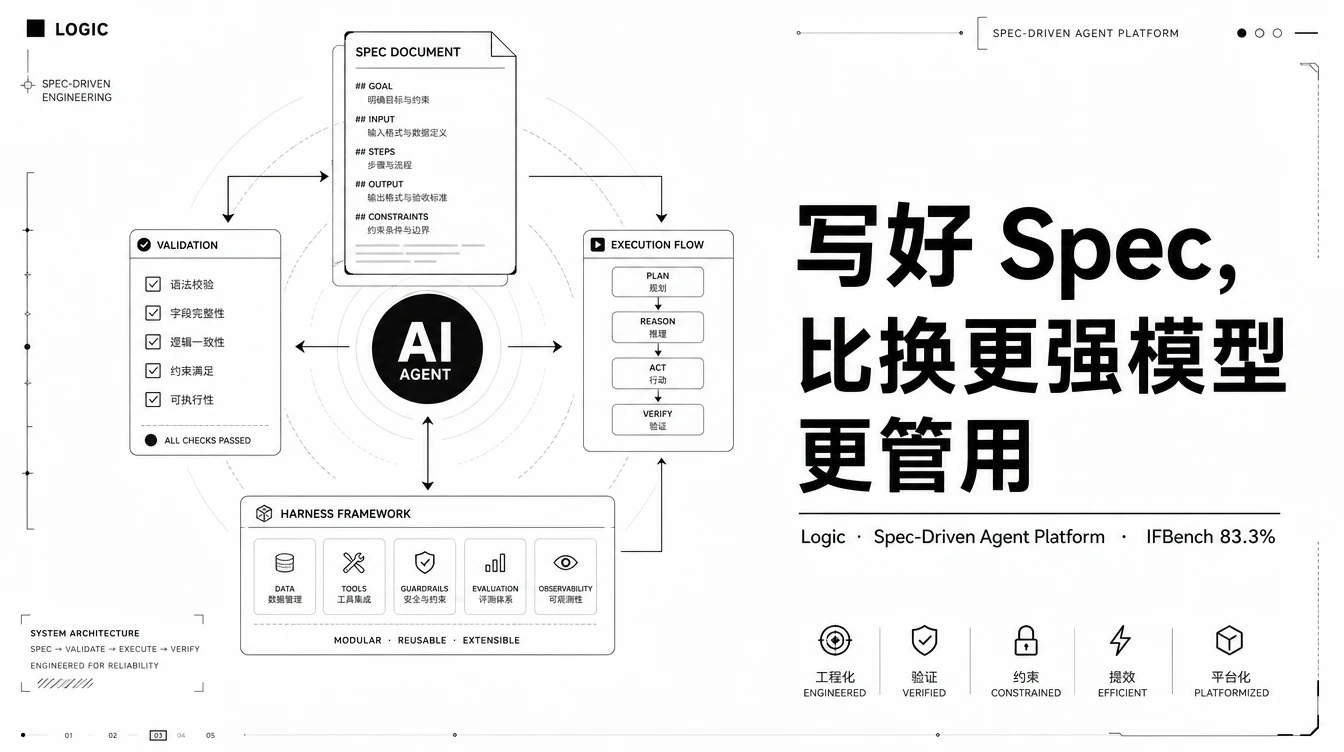
Logic 这个平台值得所有做 Agent 的人关注,因为它用事实证明了一件事,写好 spec 比换更好的模型管用。
一件事
4 月 27 日,西雅图创业公司 Logic 宣布正式上线 spec-driven 的 Agent 平台。同一天,他们放出了 IFBench 跑分结果:同一个 Gemini 3.1 Pro 模型,裸跑 77.1%,套上 Logic 的 harness 加 spec 之后 83.3%,直接登顶 Artificial Analysis 的 IFBench 公开排行榜。
6 个点的提升,不需要换模型,不需要加参数,只需要写一段 500 字的规格说明。
为什么这个结果重要
IFBench 是 Allen AI 在 NeurIPS 2025 发表的基准测试,专门测一件事:模型能不能在第一次遇到某个约束条件时,就严格遵守它。294 个任务,每个 prompt 里塞了多个可验证的精确约束,比如 "三句话必须字符数相同但用词全部不同"、"逐行递进缩进"。评分是确定性的,Python 验证器逐条检查,没有部分得分,没有重试机会。
在这个基准上,换一个更强的模型通常只移动几个百分点。而 Logic 的实验表明,给同一个模型加上一个好 spec,移动的幅度比换模型还大。
spec 长什么样
Logic 的核心逻辑是:你写 spec(用自然语言描述 Agent 应该做什么),平台自动生成 schema、测试、工具路由、版本控制、可观测性。spec 本身大约 500 词,核心步骤非常简单:
- 仔细阅读 prompt,识别任务和所有约束条件
- 先起草回答,关注任务本身
- 逐条对照每个约束检查
- 不满足就改,直到全部通过
- 只返回最终回答,不要解释
对,就是你会给一个认真干活的人类下属说的那些话。问题在于,大多数人给模型写 prompt 的时候,不会写这么详细。
Harness 的角色
spec 是一半,另一半是 Logic 的 harness。它自动做输入验证、结构化输出约束、调用路由、契约执行。这些本来是每个 Agent 项目都要自己搭的基础设施,Logic 把它变成了平台能力。
用 Logic CEO Steve Krenzel 的话说:"两年前每个做 AI feature 的团队都在从零搭 LLM 基础设施,把这种工作正在变成商品,这其实是好事。"(
实操启示
如果你在做 Agent 开发,这个实验给了一个非常具体的行动建议:在考虑换模型之前,先花 30 分钟把你的 spec 写清楚。不是写得更长,是写得更结构化:任务是什么、约束有哪些、检查步骤是什么、输出格式长什么样。
Logic 已经有超过 250 家机构在使用,累计跑了 400 万次 Agent 调用,覆盖医疗、电商、金融安全等领域。平台支持 OpenAI、Anthropic、Google 三家模型路由,免费层可以直接上手。
我的看法
Logic 做的事情本质上是在验证一个假设:Agent 的质量瓶颈不在模型,在于模型外面的那层工程。spec 是 prompt engineering 的升级版,harness 是 context engineering 的产品化。当这两件事结合在一起,同一个模型就能跑出更好的结果。
这个方向和 Anthropic 的 Programmatic Tool Calling、OpenAI 的 Symphony 是同一条脉络:让工程结构承担更多控制责任,把模型解放出来做它擅长的事。区别是 Logic 更激进,它直接说:别写代码了,写 spec 就行。