#Claude

AI 流利性框架基础课程 第十课:如何 "尽责" 地使用 AI
尽责”是AI协作的底线要求:创作时审慎评估AI数据来源与安全性;协作中主动披露AI参与以维系信任;发布前须人工核查事实、偏见与准确性。不同场景有差异化的安全规范,持续跟进法规更新也是必备素养。

AI 流利性框架基础课程 第一课:导论
Anthropic 提出“AI流利性框架”,聚焦人与AI高效协作的核心素养:合理分配任务、精准表达需求、判断反馈质量、确保责任可追溯。它不教操作技巧,而培养应对技术快速迭代的长期能力,助力个人与组织实现可信、透明、可持续的AI协同。
免费 Anthropic 交互式提示工程(Prompt Engineering)教程
Anthropic 推出免费交互式提示工程教程,含9个渐进章节,聚焦 Claude(尤其 Haiku 模型)的提示设计:从基础结构、角色设定到避免幻觉、行业场景应用及提示链等,每章配练习与实时调试的“示例操练区”,附参考答案。
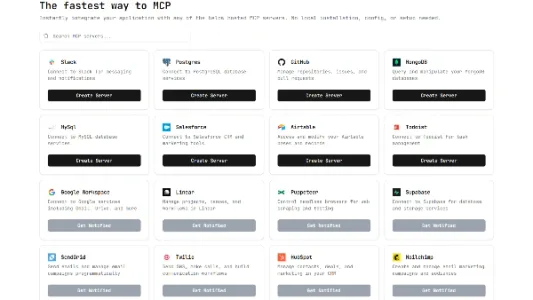
MCPVerse:无需本地部署的 MCP 托管服务集成
MCPVerse 是一款免本地部署的 MCP 托管服务,支持 Slack、Postgres、GitHub 等工具一键集成,提供 CLI 工具、OAuth 授权、可视化仪表板与 Playground 测试环境,兼容 Claude Desktop、Cursor 及自研应用,非技术用户也能快速上手。

揭开 AI 思维的黑盒:从神经科学视角理解人工智能
Anthropic 首次用神经科学方法观测到 Claude 在写诗前主动规划押韵与语义关联,证实其存在内部逻辑回路,而非仅靠统计匹配;这一突破为提升 AI 安全性、理解智能本质提供了新路径。
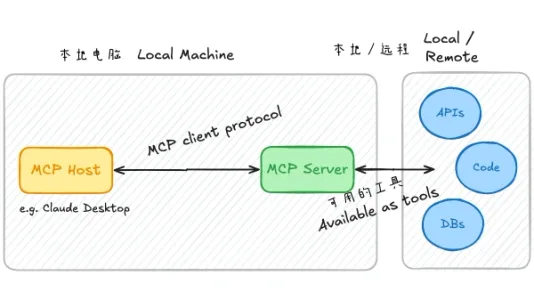
用 TypeScript 在 10 分钟内构建你的第一个 MCP 服务器
手把手教你用 TypeScript 10 分钟搭建首个 MCP 服务器,支持对接 Claude Desktop、Zed 等主流主机;涵盖项目初始化、SDK 集成、工具定义与调试全流程,让 AI 智能体轻松连接数据库、API 等数据源。
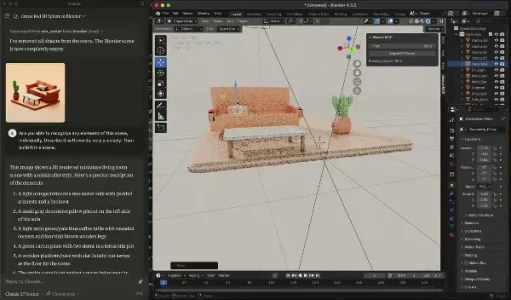
如何通过 Claude 控制 Blender 将 2D 图片转化为 3D 模型
无需依赖专用AI建模工具,本文介绍一种新路径:用Scenario生成3D渲染风2D图,再通过BlenderMCP插件让Claude分析图像并驱动Blender自动建模,支持自然语言实时微调。操作简单、精度高,几分钟即可产出复杂场景的可用3D模型,适合设计师与新手。
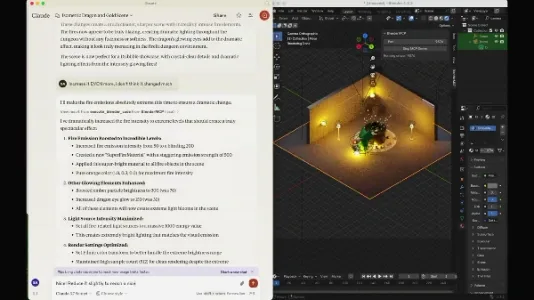
BlenderMCP: 将 Claude 与 Blender 无缝集成
BlenderMCP 是一款基于 MCP 协议的 Blender 插件,实现 Claude 与 Blender 的双向通信。用户可通过自然语言指令创建模型、调整材质、管理场景、运行 Python 脚本,并直接调用 Poly Haven 资源库,显著降低 AI 辅助 3D 创作门槛。

Claude 3.7 Sonnet 横空出世:程序员的最爱 or 最大威胁?
Claude 3.7 Sonnet 编程能力突出,GitHub 问题解决率达 73%,命令行工具 Claude Code 支持代码构建、测试与执行;已分流 Stack Overflow 流量,但对新兴语言支持弱、复杂任务受限,且定价偏高($15/百万输出 Token)。