#AI 模型

在手机高效跑模型的神器:Nexa AI
Nexa AI 是一款移动端本地模型推理引擎,支持 Android/iOS 及 NPU/GPU/CPU 多硬件加速,在手机端实现低功耗、高效率的语音转写、图像识别与图文音多模态搜索;SDK 简洁,几行代码即可集成。

小米大模型 MiMo-v2-flash 实测
小米开源MoE大模型MiMo-v2-flash,总参309B、激活仅15B,推理达150 Token/s,成本低至0.1美元/百万Token;SWE-bench多语言测试开源第一,AIME 2025表现亮眼,支持256k上下文与“思考模式”;实测1分钟生成高质量Three.js 3D避障游戏,编码能力强,手机适配稍需微调。

AI 发展简史:从图灵测试到智能体
从图灵测试、Lisp语言到深蓝、Watson,再到生成式AI与2025智能体兴起,AI历经规则驱动到数据驱动、专用走向通用的演进。当前智能体已能自主规划与调用服务,AGI与ASI的远景正引发对人机关系的深层思考。

AI 解决方案:开源 vs 闭源,如何选择?
AI解决方案涵盖模型、数据、编排与应用四层,每层均有开源与闭源选项:开源灵活可控但需自研运维,闭源开箱即用却受限于厂商。实际选型不必非此即彼,可按需混搭——如开源模型+闭源编排,兼顾性能、安全与效率。

Grok 4.1 到底好不好用
Grok 4.1在LMArena登顶,但实测优势集中在实时抓取X平台最新推文,适合舆情分析与事件追踪;响应慢、编程能力弱、创意输出生硬是明显短板。API成本低、上手易,通用任务仍推荐ChatGPT 5.1等更成熟模型。

什么是 Transformer
2017年Google提出的Transformer,彻底抛弃RNN/CNN,仅靠注意力机制实现并行处理与长程依赖建模。其编码器-解码器结构及预训练+微调范式,成为GPT、BERT等大模型基石,推动NLP跃升,并延伸至多模态领域。
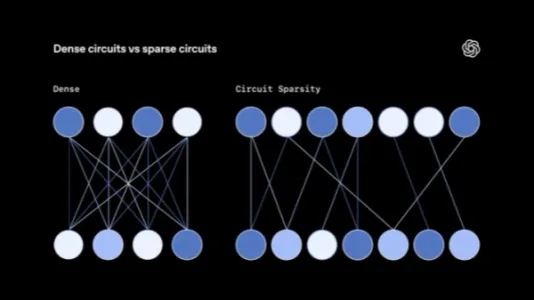
OpenAI 研究人员通过稀疏神经电路技术提升神经网络可解释性
OpenAI提出稀疏神经电路训练法,强制模型使用权重稀疏化,在小型语言模型中成功构建解耦、可追溯的最小神经电路,显著提升机械可解释性;该方法不依赖事后分析,为理解大模型内部机制提供了新路径。

大模型与人类大脑电量消耗对比
OpenAI计划部署耗电10吉瓦的新系统,堪比小型城市;而人类大脑日均仅耗电约20瓦,效率高出数百万倍。文章对比大模型训练与推理的高能耗现状,指出当前AI在电力与散热上的巨大压力,并强调向人脑学习节能设计、优化算法与硬件,是实现可持续AI的关键路径。

Google 的 Gemma AI 模型帮助发现新的潜在癌症治疗途径
Google基于Gemma构建的270亿参数单细胞模型C2S-Scale 27B,发现CK2抑制剂西米他塞替可在低干扰素环境下特异性增强肿瘤抗原呈递,使“冷”肿瘤变“热”,该预测已在体外实验中验证有效,为癌症免疫联合疗法提供新线索。