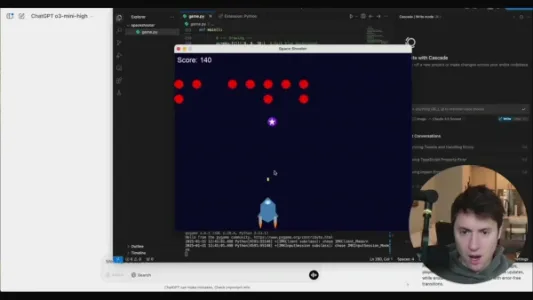
如何使用 OpenAI o3-mini 实现零代码游戏开发
OpenAI 新推推理模型 o3-mini,免费用户每日可调用 10 次。科技达人 Alex Finn 演示仅用一行提示词,即可生成含全部资源与规则的 Python + Pygame 太空射击游戏,并支持自然语言实时修改,5 分钟完成零代码开发。
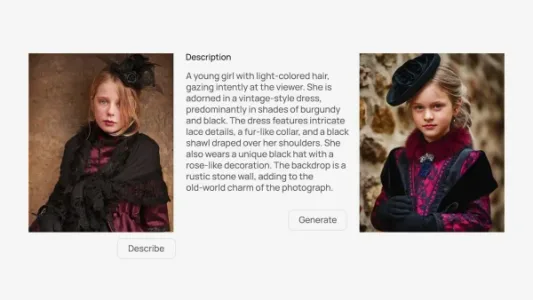
Ideogram 推出图像复刻功能
Ideogram 新增图像复刻功能,上传原图即可自动生成高保真“克隆版”,尤其擅长精准还原图中文字;支持在复刻基础上叠加创意调整,适合需保留关键视觉元素又想二次创作的用户。

九大 AI 视频模型对比:林中白虎
AIGC达人Heather Cooper用“林中白虎”统一提示词,实测Google Veo 2、Sora、腾讯混元等九大AI视频模型。聚焦生成质量、镜头语言与氛围表现力,直观呈现当前文生视频技术的多强格局与差异化能力。

OpenAI 发布最新推理模型 o3-mini:性能提升,首次向免费用户开放
OpenAI发布轻量推理模型o3-mini,首次向免费用户开放。支持函数调用、结构化输出与三档推理强度调节,在STEM任务中错误率降低39%,响应速度比o1-mini快24%。已上线ChatGPT及API,兼顾精度、速度与安全性。
自动将网站转化为结构化数据 API 的开源工具:LLM API Engine
LLM API Engine 是一款开源工具,能将任意网站(如雅虎财经)自动转为结构化数据 API。用户只需定义字段(如股价、交易量)和目标网址,系统即通过 Firecrawl 解析网页、OpenAI 验证结构、Upstash 存储数据,并生成可部署于 Cloudflare Worker 或 AWS Lambda 的实时 API,支持定时自动更新。
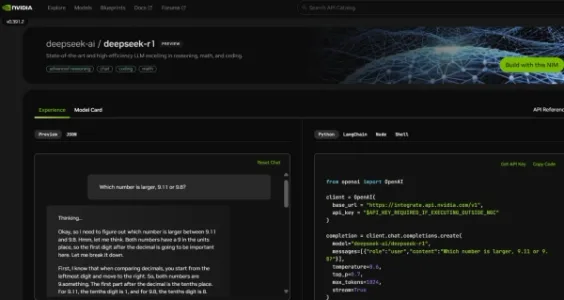
DeepSeek-R1 现已通过 NVIDIA NIM 微服务上线
DeepSeek-R1——6710亿参数开源MoE大模型,支持思维链、共识推理等测试时扩展能力,在逻辑、数学、编程任务中表现突出。现通过NVIDIA NIM微服务上线,单台HGX H200可达3872 tokens/s,支持企业级安全部署与智能体定制开发。

如何结合 Ollama 和 DeepSeek-R1 创建一个本地聊天机器人
无需联网,用 Ollama 本地运行 DeepSeek-R1 模型,搭配 Python + Gradio/Streamlit 快速搭建离线聊天机器人。支持流式响应、多轮对话与界面交互,兼顾隐私安全与开发实践价值,附完整可运行代码。
Krea.ai + DeepSeek AI 绘画视频生成新方式
Krea.ai 与 DeepSeek 深度融合,支持自然语言对话式操作,自动理解用户意图并生成高质量提示词,兼容 Flux、Ideogram、可灵、海螺等主流绘图与视频模型,零提示词基础也能高效创作。

香港科技大学研发的开源音乐生成模型:YuE
香港科技大学开源音乐生成模型YuE,支持中英日韩四语,可依歌词生成最长5分钟、含主唱与伴奏的完整歌曲,强调结构连贯性与旋律表现力,为创作者提供Suno、Udio之外的新选择。