
什么是 CrewAI?
CrewAI 是一个基于 Python 的智能体框架,模仿人类项目团队协作模式,支持创建角色明确、分工专业的 AI 智能体(如编码专家、测试工程师),并实现跨角色协同。兼容多厂商大模型与外部工具,适合处理需多角色配合的复杂任务。
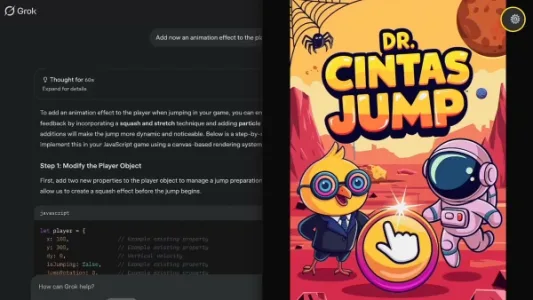
如何通过 Grok 3 快速开发一个完整的游戏
技术达人Alvaro Cintas仅用数小时,借助Grok 3从零开发出一款功能完整的竖版跳跃游戏,涵盖角色、怪物、平台、难度与生命系统。他采用“先跑通再美化”策略:首步生成单文件HTML/CSS基础代码(形状代替素材),再用AI批量产出风格统一的视觉资源,最后逐步叠加动画、菜单与敌人等细节。
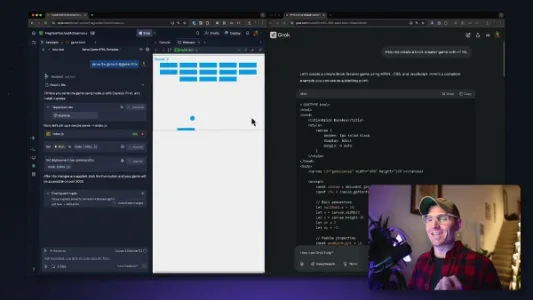
如何零代码使用 Grok 在 Replit 上创建并部署应用
无需写代码,用 Grok 生成逻辑,再通过 Replit 一键部署——比如已上线的打砖块游戏(https://brick-breaker-grok.replit.app),普通人也能快速做出可访问的 Web 应用。
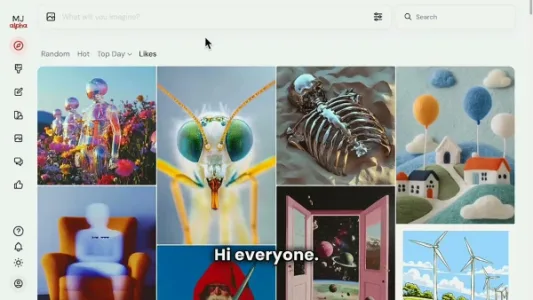
Midjourney 作品整理功能使用教程
Midjourney上线作品整理功能,支持以文件夹(标签)形式对生成图进行分类管理:创建或浏览时自动归入对应文件夹,图片可归属多个文件夹,分组归类更清晰;灯箱中直观展示,右键即可批量下载,拖拽或点击按钮均可快速添加图片。

一站式 AI 创作平台 Pollo.ai 使用教程
Pollo.ai 整合可灵、海螺、Pika、Runway、Luma 等主流 AI 视频模型,支持创作中自由切换,兼顾质量与效率。新手推荐先观看科技达人 Ben 的实操教程,快速上手核心功能与实用技巧。

RAG 和 模型微调哪个好,怎么用?
RAG借助外部向量库实时检索信息,成本低、易更新,适合需动态数据的场景;模型微调则通过领域数据训练提升专业性与准确性,但耗资源且知识静态。二者并非互斥,常结合使用——RAG补时效,微调强专精。

10 分钟讲清什么是大模型的尺度定律(Scaling Law)
大模型尺度定律揭示参数、数据与算力需协同扩展,盲目堆参数反会降低效率——Chinchilla研究已证实小模型配更多数据效果更优。当前高质量数据成新瓶颈,合成数据与MoE架构正成为突破关键。

HuggingFace 推出了免费智能体(AI Agent)开发课程
Hugging Face 推出免费 AI 智能体开发课程,涵盖原理、设计与实战,支持 smolagents、LangChain、LlamaIndex 等主流框架;学员可发布智能体至 Hugging Face Hub、参与社区挑战与横向评估,完成作业后获官方结业证书。

从 V0 到 R1,deepseek 如何追平 GPT-4
DeepSeek 两年内从2023年V0迭代至2025年R1,在数学、逻辑与编程能力上追平GPT-4;通过MoE、MLA等架构创新,参数达6710亿,并以跨架构蒸馏技术实现高性能轻量部署,标志AI研发正转向“能力驱动”。