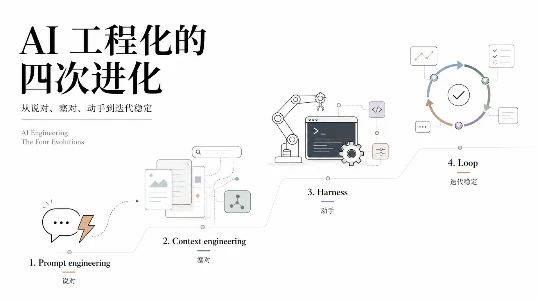
过去三年,AI 应用开发者的核心技能是提示词工程,怎么写好一句指令,让模型输出你想要的结果。
这个思路在 2023 到 2024 年很有效。那时候模型本身是短板,你写提示词的方式直接决定输出质量。
2026 年的情况不一样了。Anthropic 在 4 月 16 日发布 Claude Opus 4.7,测试方普遍报告它在长时任务上的可靠性明显提升。Notion Agent 在 Opus 4.7 上工具调用错误减少三分之一,第一次通过了隐式需求测试。Rakuten-SWE-Bench 上任务解决量是 Opus 4.6 的三倍。
这不是个例。当模型能力普遍越过某个门槛之后,真正决定应用质量的不再是模型够不够好,而是上下文有没有放对。
模型够了,上下文字成瓶颈
Logic.inc 在 4 月 16 日发布了一份上下文工程指南,开头说了一段话,值得玩味。
当你的 Agent 在生产环境里失败的时候,很少是因为 Claude 或者 OpenAI 的模型处理不了这个任务。失败几乎总是来自上下文窗口,文档不对、内存过期、工具输出缺失,或者指令在十五轮对话后开始自相矛盾。
这段话概括了过去一年行业认知的转变。
Artinoid 的一篇文章把这个逻辑讲得更清楚。它把上下文窗口比喻成 RAM,把 LLM 比喻成 CPU,你的角色是操作系统,在任何一个时间点往工作内存里加载恰好需要的数据。加载太少,模型没有足够信息工作。加载太多无关内容,性能下降,成本上升。
这个比喻解释了为什么提示词写得更好不再能解决大部分生产级问题。
上下文工程具体在管什么
根据 Logic.inc 的梳理,生产环境里 Agent 的上下文由七个层次构成:
系统提示词、工作输入、检索到的知识、工具输出、对话历史、结构化中间结果、跨会话状态和记忆。
每个层次有不同的失效模式。工具输出可能格式错误。对话历史可能稀释早期指令。检索到的文档可能已经过期。Logic.inc 特别指出,在这七个层次里出错,把其中一个搞对也可能被其他几个的失效抵消。
Artinoid 把这个问题命名为上下文腐烂(context rot)。当上下文窗口被不再相关的信息填满,模型的注意力被分散,信噪比下降,输出质量在无声中恶化。
这不是可以通过换模型解决的性能问题。它的本质是信息架构问题。
模型厂商测解决方案
Anthropic 的 Opus 4.7 发布里有一个细节,他们在发布工具使用相关的三个新特性,Tool Search Tool、Programmatic Tool Calling、Tool Use Examples。这三个特性的共同点是帮助开发者更好地管理 Agent 的工具定义和调用上下文。
这不是在改进模型本身,而是在改进模型和外界的连接层。
Logic.inc 也引用了一个具体数据:RAG-MCP 模式(把工具选择当成检索问题来处理)相比基线将工具调用准确率从 14% 提升到 43%,同时减少超过 50% 的提示词 Token 消耗。这个数字说明上下文管理的优化可以直接转化为可测量的工程收益。
我的看法
这两个趋势放在一起,指向了一个明显的方向。AI 应用开发正在从模型调用变成系统设计。过去三年,壁垒是模型的能力。接下来三年,壁垒将在上下文架构。
这并不意味着提示词不重要。Anthropic 在 Opus 4.7 的迁移指南里特别提到,Opus 4.7 的指令遵循能力大幅提升,这意味着之前写给老模型的提示词可能需要重新调校,因为新模型会严格按照字面意思执行,而不像老模型那样会灵活绕过不明确的地方。
但这个调整是工程层面的,不影响大方向。
对于正在做 AI 应用的团队,真正值得投入的不是继续调提示词,而是回答三个问题:
你的 Agent 现在上下文里放了什么,哪些是真正需要的,什么时候应该清空?
这几个问题看起来基础,但实际上大部分团队没有认真检查过自己的上下文窗口里到底装了什么。答案决定了你的应用能不能稳定跑过长任务。