作者:Erik Pounds
翻译:零重力大理
原文链接:https://blogs.nvidia.com/blog/deepseek-r1-nim-microservice
DeepSeek-R1 简介
DeepSeek-R1 是一款开源模型,具备最先进的推理能力。与那些直接给出回答的传统模型不同,DeepSeek-R1 推理模型会对用户的提问进行多次推理迭代,采用 “思维链”(chain-of-thought)、共识(consensus)和搜索等方法,生成最佳答案。
这种多次推理迭代的过程被称为测试时扩展(test-time scaling)。DeepSeek-R1 是这一扩展法则的完美范例,展示了加速计算对满足智能体 AI 推理需求的关键性作用。通过允许模型反复“思考”问题,生成更多的输出 Tokens 和更长的生成周期,模型的质量得以持续提升。因此,测试时计算能力对于实现推理模型的实时推理和高质量输出至关重要,需要部署更大的推理计算资源。
DeepSeek-R1 在逻辑推理、数学、编程和语言理解等任务上具有很高的准确性,同时也具备高效的推理性能。
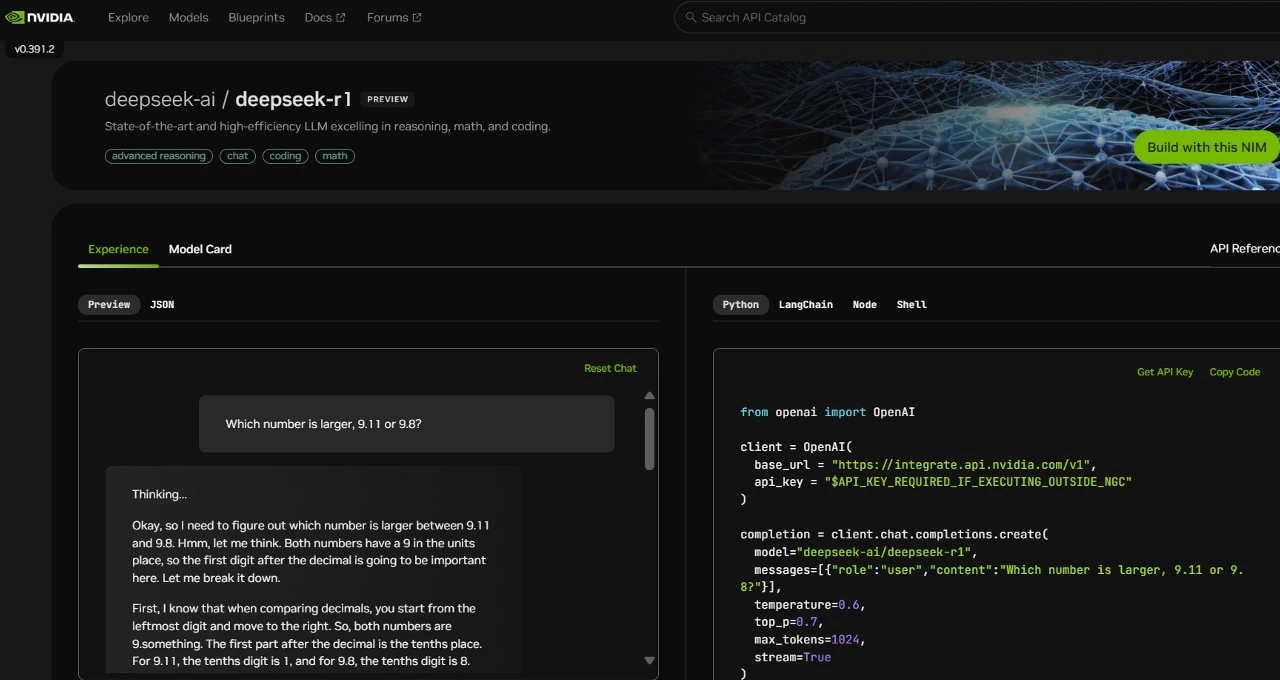
DeepSeek-R1 NIM 微服务现已推出
为了帮助开发者安全地探索这些功能并构建专属的智能体,英伟达现已通过 build.nvidia.com 将这款拥有 6710 亿参数 的 DeepSeek-R1 模型作为 NVIDIA NIM 微服务提供给开发者。DeepSeek-R1 NIM 微服务在单台 NVIDIA HGX H200 系统上,每秒可以生成高达 3872 个 Tokens。
开发者可以测试和实验其应用程序的接口(API),该接口预计将很快作为 NVIDIA NIM 微服务的一部分发布,并纳入 NVIDIA AI Enterprise 软件平台中。
DeepSeek-R1 NIM 微服务支持行业标准的 API,简化了部署流程。企业可以通过在其首选的加速计算基础设施上运行 NIM 微服务,最大限度地确保数据隐私和安全性。此外,借助 NVIDIA AI Foundry 和 NVIDIA NeMo 软件,企业还可以定制化 DeepSeek-R1 NIM 微服务,用于开发专属的智能体。
DeepSeek-R1:测试时扩展的完美典范
DeepSeek-R1 是一款大规模混合专家模型(MoE,Mixture-of-Experts),拥有 6710 亿参数,其规模是许多其他开源大型语言模型的 10 倍。该模型支持 128000 个 Tokens 的超长输入上下文,并在每一层使用极高数量的专家节点。
在 DeepSeek-R1 的每一层中,有 256 个专家节点,每个令牌会被并行分配给其中的 8 个专家节点进行评估。这种架构允许模型实现实时推理,但需要大量 GPU 具备高计算性能,并借助高带宽、低延迟的通信机制,将输入Tokens 传递给所有专家节点进行推理。
结合 NVIDIA NIM 微服务的软件优化功能,一台配备 8 块 H200 GPU 的服务器,通过 NVLink 和 NVLink Switch 互联,可以运行完整的 6710 亿参数的 DeepSeek-R1 模型,并实现每秒高达 3872 个Tokens 的吞吐量。这一性能得益于 NVIDIA Hopper 架构的 FP8 Transformer 引擎 和 900 GB/s NVLink 带宽,用于专家节点之间的通信。
为了实现实时推理,充分利用 GPU 的每一次浮点运算是至关重要的。下一代 NVIDIA Blackwell 架构将为 DeepSeek-R1 等推理模型的测试时扩展提供强大支持,其第五代张量核心(Tensor Core)峰值 FP4 计算性能可达 20 PFLOPS,并配备专为推理优化的 72-GPU NVLink 域。

开发者可以通过 build.nvidia.com 提供的 NVIDIA NIM 微服务进行智能体及各种应用的开发。