
虽然视觉语言模型在构建用户界面(UI)已经有相当不俗的表现,但它们的潜力仍没有被充分发掘。其中一个重要的原因在于它们还无法准确识别用户界面中各种元素的含义,并将它们与用户想要执行的操作关联起来。
OmniParser 介绍
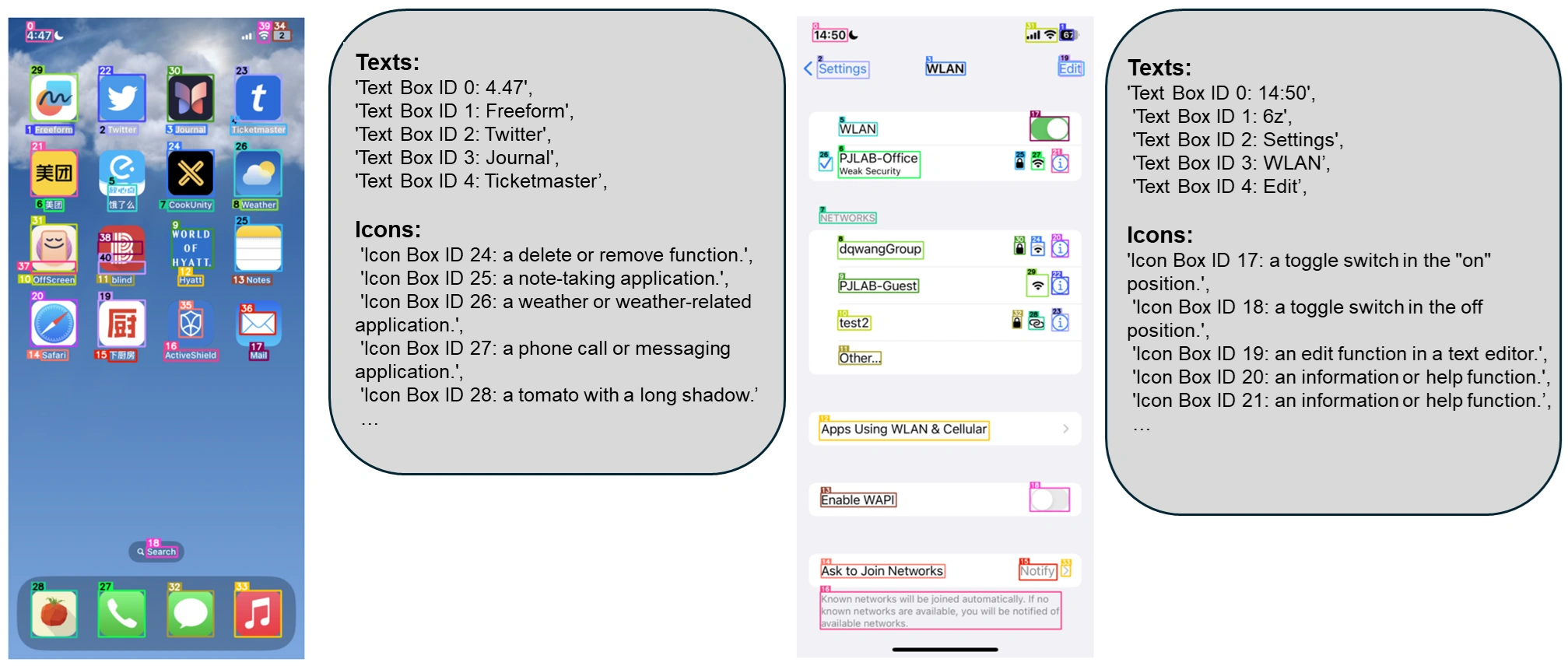
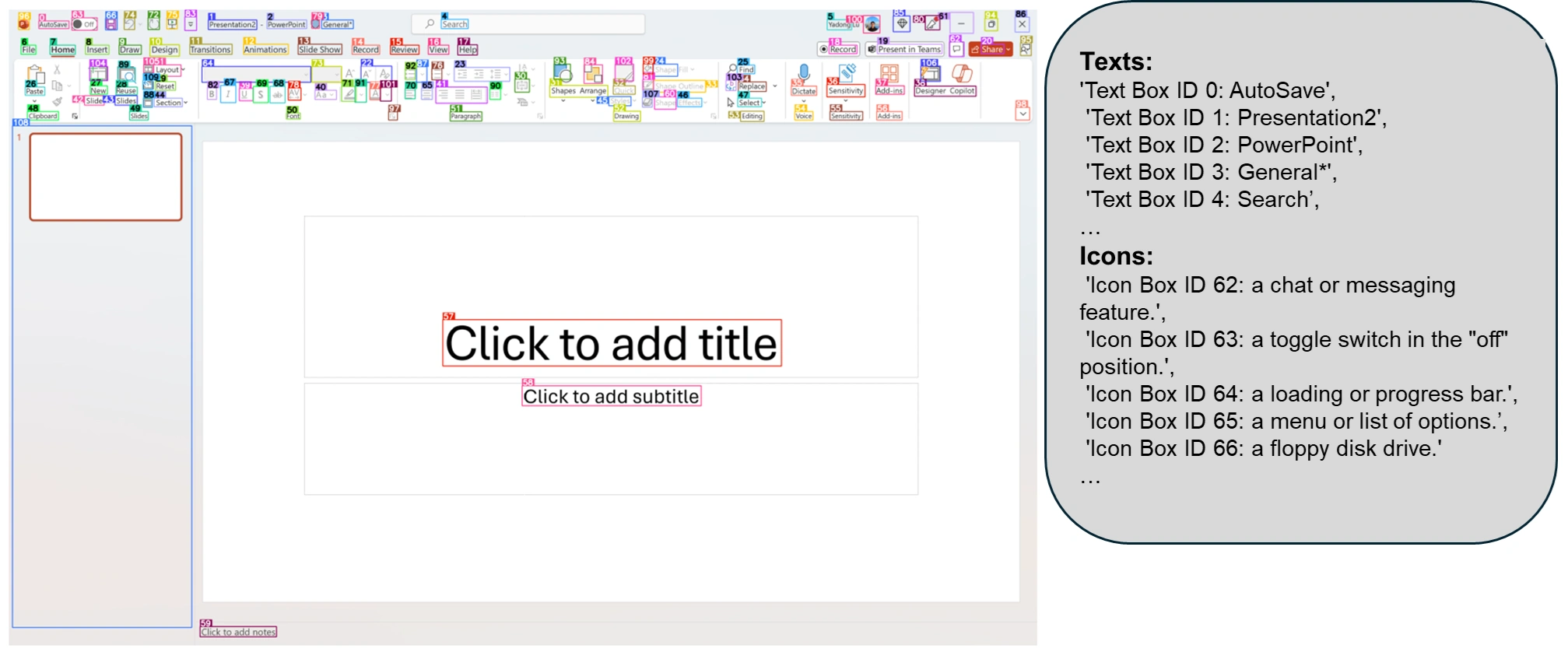
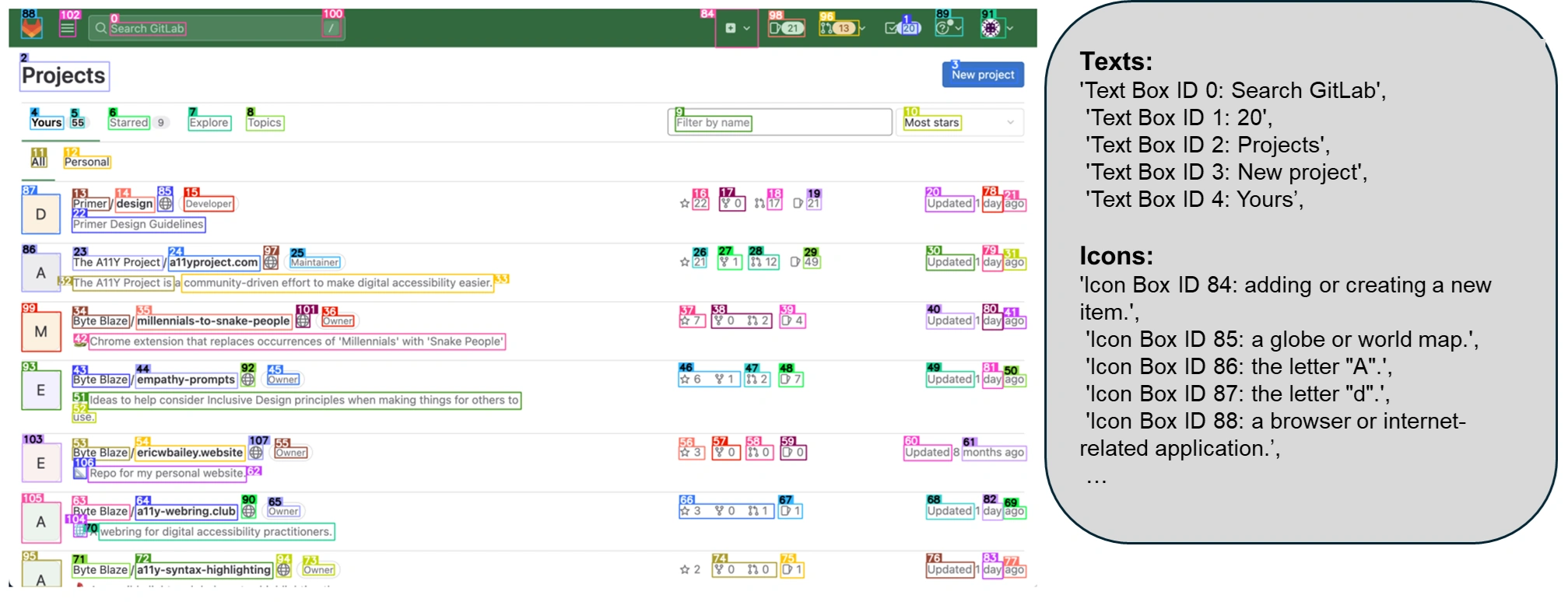
为了弥补这些不足,微软的研究人员提出了 OmniParser。这是一种可以将用户界面的截图解析成结构化元素,并帮助 GPT-4V 生成与之匹配代码的方法。
数据集构建
研究者们首先收集了一个包含 67000 个独特截图的可互动图标检测数据集,并从每个网页的 DOM 树中提取了可互动区域的边界框。此外,他们还收集了 7000 对图标和描述的配对,以帮助模型更好地理解图标的功能。
结果评估
在多个基准测试(SeeClick、Mind2Web和AITW)中,OmniParser 的表现都超过了 GPT-4V 的基线,并且在只使用截图输入的情况下,OmniParser 的效果也优于需要额外信息的 GPT-4V 模型。
插件兼容性
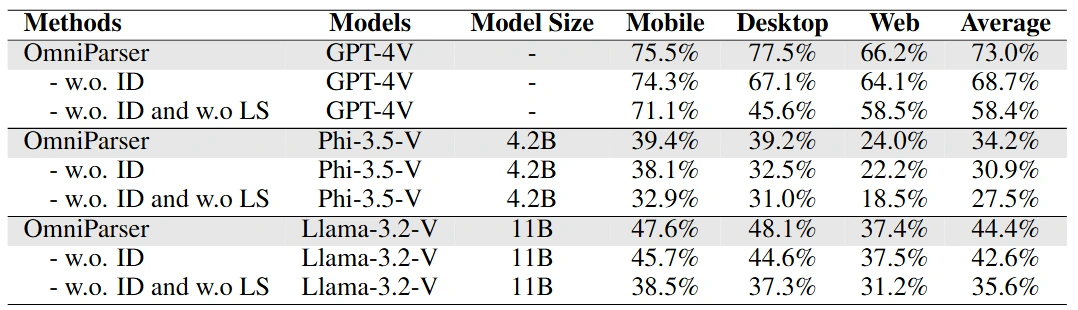
OmniParser 还可以作为插件,与其他视觉语言模型(如Phi-3.5-V 和 Llama-3.2-V)结合使用,进一步提升这些模型的性能。研究显示,通过使用OmniParser,模型在任务执行上的表现都有显著提高,尤其是在理解图标功能和区域检测方面。
总结
OmniParser 技术的引入,能够帮助视觉语言模型更好地理解用户界面,提升了它们在各种任务中的表现。这将使得未来的智能系统在与用户互动时更加高效和准确。
OmniParser 项目地址
评论(0)