
目前,除了 DeepSeek、ChatGPT o 系列模型,以及仍处于实验阶段的 Gemini 2 Flash Thinking 之外,其他大模型尚不具备完整的思维链(Chain of Thought, CoT),因此无法像 DeepSeek 那样进行“深度思考”。那么,是否可以借助 DeepSeek 的思维链,对其他模型进行强化微调,使它们也具备推理能力,从而实现“深度思考”呢?
技术达人 Mervin Praison 提出了一种创新方法:通过智能体(AI Agent)协同工作,让普通模型也能具备类似 DeepSeek 和 o3-mini 的推理能力。而且,整个方案的代码仅需一页!
大家也可以直接访问 Mervin Praison 开发的 Praison AI 框架官方网站,查看方案的详细介绍和完整代码!
核心框架:四个智能体协同工作
Mervin Praison 的方案涉及四个核心智能体,分别承担不同的任务:
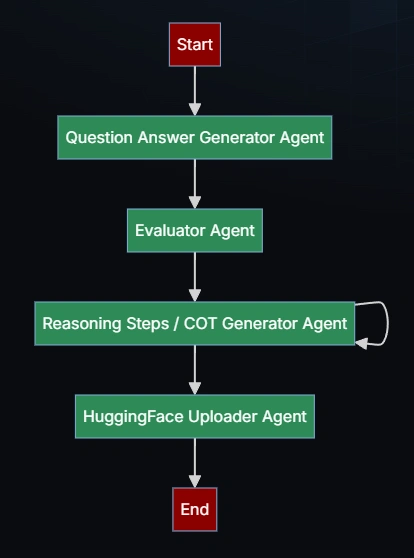
- 问答生成器(Question Generator):自动创建高质量的问答对。
- 评估器(Evaluator):检查生成的问答质量,确保数据的准确性和合理性。
- 推理步骤生成器(Reasoning Step Generator):为每个问答对添加详细的推理过程,构建完整的思维链。
- 数据上传器(Data Uploader):将最终数据集上传到 Hugging Face 以供微调训练。
如何实现?
整个流程非常简洁高效,开发者只需编写必要的代码、配置智能体,并启动自动化流程,系统便会:
✅ 自动生成 10 组独特的问答对
✅ 为每个问题生成完整的思维链,包括问题分解、推理步骤及最终答案
✅ 自动上传数据集,便于用于后续微调
实现代码
安装软件包
首先,安装 PraisonAI Agents 软件包:
pip install "praisonaiagents[llm]" datasets huggingface-hub pandas
设置 API 密钥
在终端中将你的 OpenAI API 密钥 设置为环境变量:
export OPENAI_API_KEY=your_api_key_here export HF_TOKEN=your_huggingface_token_here
创建文件
新建一个名为 app.py 的文件,并进行基本设置:
from praisonaiagents import Agent, Task, PraisonAIAgents
from praisonaiagents.tools import cot_save, cot_upload_to_huggingface
from pydantic import BaseModel
import os
# Define Pydantic model for structured output
class DecisionModel(BaseModel):
response: str
decision: str
def write_csv(file_path, data):
"""Write data to CSV file."""
if not os.path.exists(file_path):
with open(file_path, 'w') as file:
file.write(data + '\n')
else:
with open(file_path, 'a') as file:
file.write(data + '\n')
return f"Data appended to {file_path}"
def count_questions(file_path):
"""Count lines in file."""
with open(file_path, 'r') as file:
return sum(1 for _ in file)
# Create specialized agents
qa_generator = Agent(
name="Generator",
role="Question Creator",
goal="Create challenging math and logic questions",
backstory="Expert in educational content creation",
llm="gpt-4o-mini",
tools=[write_csv, count_questions]
)
total_questions_evaluator = Agent(
name="TotalQuestionsEvaluator",
role="Total Questions Evaluator",
goal="Evaluate the total number of questions in qa_pairs.csv file",
backstory="Expert in evaluating the total number of questions in a file",
llm="gpt-4o-mini",
tools=[count_questions],
verbose=False
)
cot_generator = Agent(
name="COTGenerator",
role="Chain of Thought Specialist",
goal="Generate and manage chain of thought solutions for Q&A pairs",
backstory="Expert in breaking down problems and generating detailed solution steps",
tools=[cot_save],
llm="gpt-4o-mini",
verbose=False
)
upload_to_huggingface = Agent(
name="UploadToHuggingface",
role="Upload to Huggingface",
goal="Upload the generated chain of thought solutions to a Huggingface dataset",
backstory="Expert in saving data to Huggingface",
tools=[cot_upload_to_huggingface],
llm="gpt-4o-mini",
verbose=False
)
# Define tasks with workflow
generate_task = Task(
description="""Generate question and answer in csv format without headers: question, answer and append to qa_pairs.csv file
generate 10 unique questions and answers and don't repeat on the same question and answer. Reponse with 'done' when done
with append mode as 'a'
Example question and answer:
question, answer
What is the sum of numbers from 1 to 10?, 55
Number of r's in the word strawberry, 3
""",
expected_output="append to qa_pairs.csv file with questions and answers and move to next task",
agent=qa_generator,
name="generate_task",
is_start=True,
next_tasks=["evaluate_total_questions"],
task_type="decision",
condition={
"more": "generate_task",
"done": "evaluate_total_questions"
}
)
evaluate_total_questions_task = Task(
description="Evaluate the total number of questions in qa_pairs.csv file is 1",
expected_output="Total number of questions in qa_pairs.csv file",
agent=total_questions_evaluator,
task_type="decision",
name="evaluate_total_questions",
condition={
"more": "generate_task",
"done": "generate_cot"
}
)
generate_cot_task = Task(
name="generate_cot",
description="""Generate chain of thought solutions for each question in the input file.
Save to cot_solutions.csv file
Don't generate chain of thought solutions again after receiving the response from Tool Call
After calling the tool, respond with a JSON object:
{
"response": "done",
"decision": "done"
}
""",
expected_output="done",
agent=cot_generator,
input_file="qa_pairs.csv",
task_type="loop",
next_tasks=["upload_to_huggingface"],
condition={
"done": ["upload_to_huggingface"],
"exit": [],
},
output_pydantic=DecisionModel # Use Pydantic model for output validation
)
upload_to_huggingface_task = Task(
name="upload_to_huggingface",
description="""Upload to Huggingface:
1. Save to cot_solutions.csv
2. Upload to mervinpraison/cot-dataset""",
expected_output="Dataset published successfully",
agent=upload_to_huggingface,
tools=[cot_upload_to_huggingface]
)
# Initialize workflow
agents = PraisonAIAgents(
agents=[qa_generator, total_questions_evaluator, cot_generator, upload_to_huggingface],
tasks=[generate_task, evaluate_total_questions_task, generate_cot_task, upload_to_huggingface_task],
process="workflow",
max_iter=30,
verbose=False
)
agents.start()
运行应用程序
执行 Python 脚本,开始生成思维链(Chain-of-Thought)数据:
python app.py
这一方案的最大亮点在于高度自动化,开发者无需手动构建数据集,即可快速获得可用于训练的推理增强数据。此外,它还具备以下优势:
- 灵活定制:开发者可专注于特定领域,或输入自定义数据,打造专属训练集。
- 提升推理能力:生成的数据集可用于强化微调任何大语言模型,使其具备更强的逻辑推理能力,从而提升整体性能。
Mervin Praison 的方法为增强大模型的推理能力提供了一条全新的路径。通过智能体协同工作,即便是不具备思维链的模型,也能通过强化微调获得类似 DeepSeek 的推理能力,实现更深层次的 “思考”。
评论(0)