大模型(LLM)的应用越来越广泛,但随着模型规模的不断扩张也带来了算力、能耗与部署门槛的持续攀升。如何在保证模型能力的前提下,实现更高效的推理和更低的计算资源消耗?微软开源的 BitNet 推理框架为大模型的量化与本地部署提供了新的思路。
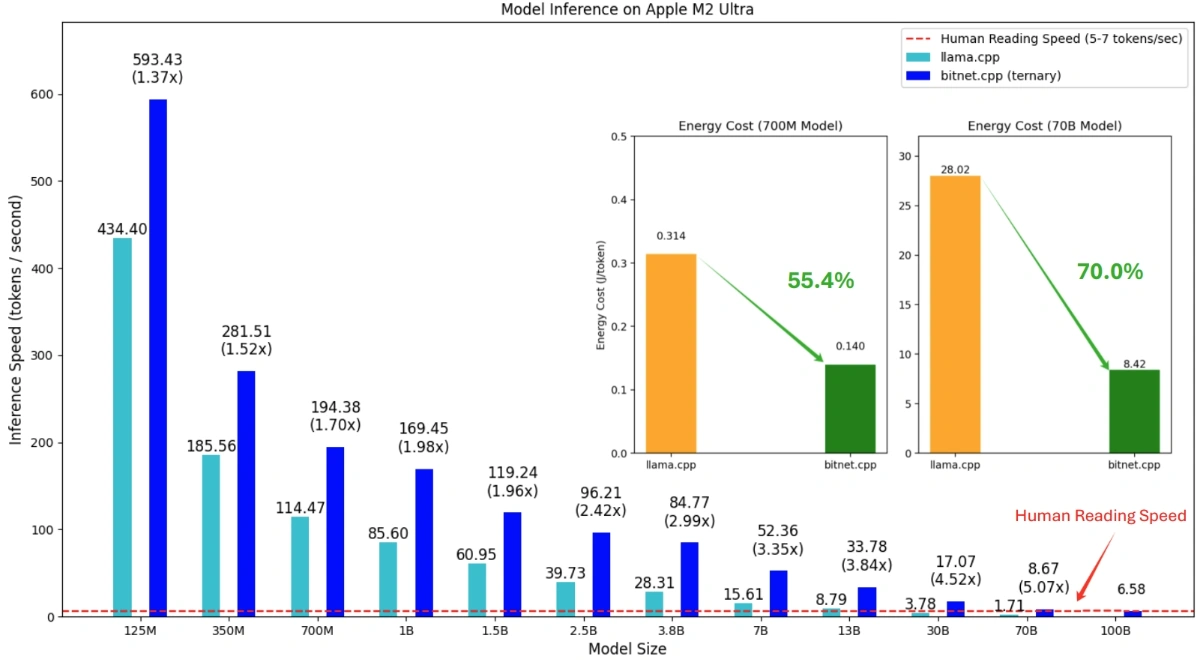
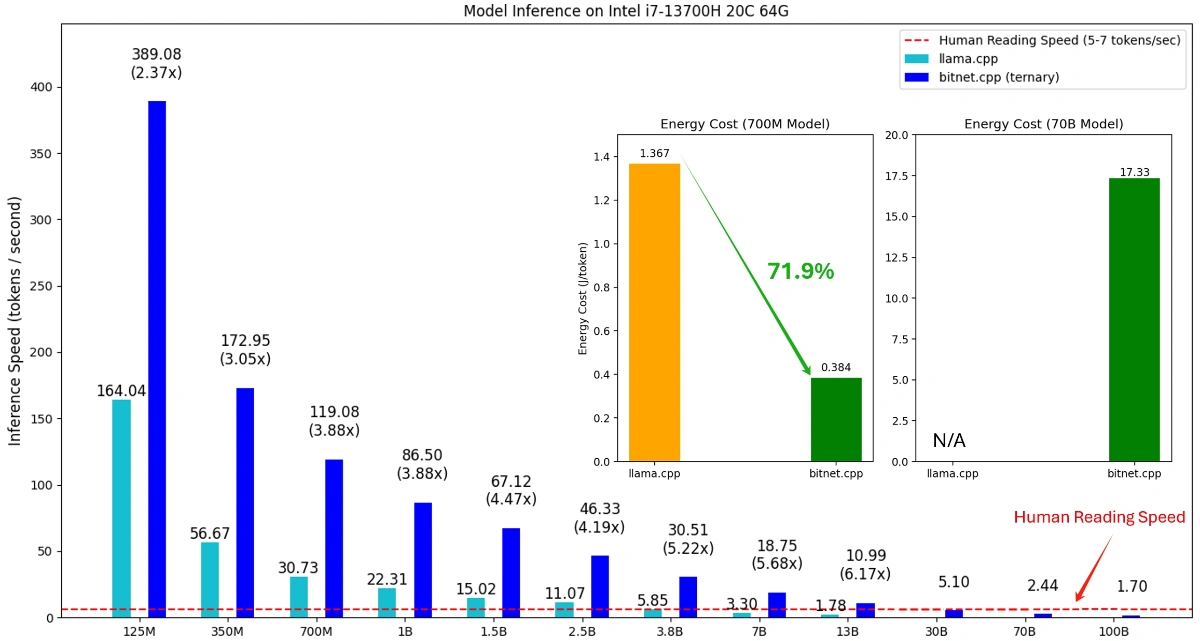
BitNet 的核心优势在于对大模型参数的极致压缩。相比主流的 8-bit 或 4-bit 量化方法,BitNet 支持 1.58-bit 乃至 1-bit 量化模型的高效推理。项目组不仅在理论上实现了低比特量化,还通过 bitnet.cpp 框架,优化了模型在 CPU 上的推理效率。实测数据显示,BitNet 在 x86 和 ARM 架构的 CPU 上均实现了巨大加速。在 x86 平台,推理速度提升了 2.37 到 6.17 倍,能耗降低 71.9% 至 82.2%。ARM 平台的加速比也达到了 1.37 到 5.07 倍,能耗减少超过一半。更具突破性的是,BitNet 能够在单台 CPU 上运行 100B 级别参数的模型,并实现 5-7 Tokens/秒 的推理速度,基本达到人类阅读的流畅度。这为本地部署超大模型提供了现实可能。
BitNet 的技术基础来自社区中广受欢迎的 llama.cpp,并进一步融入了 T-MAC 等前沿方法中的表查找优化技术,使其在低比特推理场景下依然可以保持较好的信息还原和推理准确性。对于一般低比特(非三值)模型,官方也建议结合 T-MAC 等工具,但 BitNet 在 1-bit 与 1.58-bit 领域的深度优化,显得尤为突出。
模型兼容性方面,BitNet 已支持多种主流 LLM,包括 BitNet b1.58、Llama3 1.58-bit 版本,以及 Falcon3 家族等,涵盖参数规模从 0.7B 到 10B 不等。用户可通过 Hugging Face 或自定义方式下载、部署,依托官方提供的 setup_env.py 和 run_inference.py 脚本,快速完成模型环境搭建与推理测试。值得一提的是,BitNet 不仅适配了不同 CPU 架构,也针对 x86 与 ARM 优化了内核,满足不同场景下的性能需求。

BitNet 的实现细节同样体现了对开发易用性的关注。项目支持一键脚本化安装,兼容 conda 环境,并对 Windows、Linux 等平台均有详尽的构建说明。针对常见的编译与环境问题,官方文档也给出了清晰的 FAQ 支持,降低了普通开发者的上手难度。
BitNet 的出现预示着大模型生态正在从“参数量竞赛” 转向 “推理效率” 与 “可用性” 的新阶段。过去,超大规模模型往往只能依赖高昂的 GPU 集群进行远程部署,难以在本地或边缘设备落地。随着 BitNet 等低比特推理框架的成熟,未来大模型将有望像传统软件一样,灵活运行在笔记本、手机甚至嵌入式设备上。这不仅有助于降低云端算力压力、减少能源消耗,也为数据隐私和定制化应用带来更多可能。
当然,极低比特量化带来的信息损失与模型精度之间的平衡,依然需要持续探索。但 BitNet 已经用工程化手段,打通了从模型量化、内核优化到实际推理的全流程,为大模型的普惠化、绿色化应用迈出了关键一步。未来,随着 NPU、GPU 支持的加入,BitNet 及其背后的低比特 LLM 技术,或将成为 AI 推理领域不可忽视的重要力量。
评论(0)