#强化学习

关于 “聪明得可怕” 的 Grok 3,你需要了解的一切
xAI将于2月17日发布Grok 3,马斯克称其“聪明得可怕”。依托10万H100 GPU构建的Colossus超算,结合合成数据训练、自我纠错与强化学习,显著降低幻觉、提升逻辑推理能力,在复杂任务上 reportedly 超越ChatGPT和Gemini。

从 V0 到 R1,deepseek 如何追平 GPT-4
DeepSeek 两年内从2023年V0迭代至2025年R1,在数学、逻辑与编程能力上追平GPT-4;通过MoE、MLA等架构创新,参数达6710亿,并以跨架构蒸馏技术实现高性能轻量部署,标志AI研发正转向“能力驱动”。

DeepSeek R1 是如何炼成的
DeepSeek R1 经历V1至R1 Zero四阶段迭代,融合强化学习与监督微调,采用MoE架构提升效率;仅用2048块H800 GPU即逼近OpenAI顶级模型性能,显著降低训练与推理成本,推动高效透明AI推理落地。

Open-R1:DeepSeek-R1 的完全开源复现
Open-R1 是对 DeepSeek-R1 的完全开源复现,首次公开其强化学习(R1-Zero)与监督微调+RL(R1)双路径训练方法,涵盖数据构建、代码实现与超参细节。项目聚焦数学、编程与逻辑推理,旨在推动低成本、可复现的开源推理模型发展。

最通俗易懂的 DeepSeek 核心技术介绍
DeepSeek 用“自言自语”式思维链提升推理准确性,以类婴儿试错的纯强化学习优化策略,并将6710亿参数大模型能力蒸馏至7B小模型——在数学、编程等任务上媲美甚至超越OpenAI o1,让高性能AI真正落地普通设备。
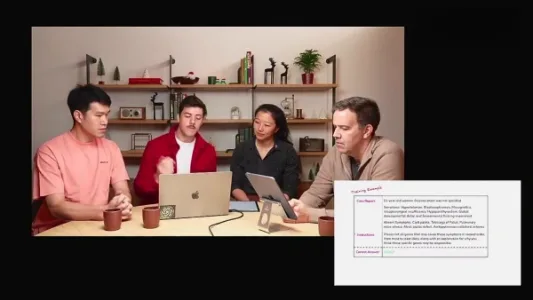
第二天:OpenAI 推出强化学习微调功能,让 AI 模型更懂"专业"
OpenAI 推出基于 o1 系列的强化学习微调(RFT)功能,仅需数十至千级专业数据(如罕见病病例)和自定义评分器,即可显著提升模型在医疗、法律等垂直领域的推理能力;微调后 o1-mini 致病基因预测准确率达 31%,远超基线。目前通过 Alpha 项目内测,明年初正式上线。

从棋盘到芯片设计:Google AI 芯片设计系统 AlphaChip
Google推出AlphaChip AI芯片设计系统,基于强化学习,数小时即可完成超越人类水平的芯片布局,已用于TPU v4/v5/v5p三代设计,并被联发科等厂商采用,加速Dimensity等旗舰芯片开发,正推动从逻辑综合到时序优化的全流程自动化。

OpenAI o1 是如何诞生的
OpenAI推出o1-preview与o1-mini,首创“思考链”推理范式:模型在回答前自主进行多步推理,受AlphaGo启发,融合监督学习与强化学习。数学推演、代码自省及抽象概念理解能力显著提升;o1-mini以轻量架构实现近似推理性能,推动深度推理能力普惠化。