
什么是 AI 芯片?
AI芯片是专为矩阵/张量运算优化的处理器,区别于通用CPU,以高并行性支撑深度学习训练与推理。GPU最早被用于AI计算,TPU、NPU等专用架构随后兴起。科技巨头与初创公司加速自研,推动AI算力从云端向手机、汽车等边缘设备下沉。

OpenAI 模型家族:功能特点与使用指南
OpenAI一年内密集推出GPT-4o、4o-mini、o1、GPT-4.5、o3、o4-mini等多款模型,定位清晰:4o-mini快而省,适合日常问答;GPT-4o全能多模态;GPT-4.5情感细腻,擅创意写作;o3是智能体,精于深度分析与图像理解;o4-mini专攻数学推理。
如何与 GPT-4o 协作并写作
GPT-4o 借鉴 GPT-4.5 预览版的“更人性化”能力,能主动提问、自适应调整文风与输出格式(如社交媒体文案或图像),在团队协作与内容创作中更懂意图、更易上手,正从工具升级为可信赖的智能协作者。
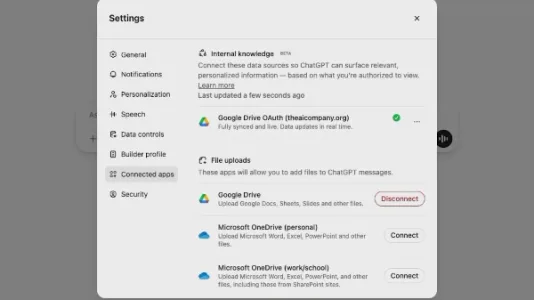
如何将通过 ChatGPT 访问和管理个人和企业内部的知识和数据
借助 Google Drive 作为知识连接器,用户可将个人或企业内部文档安全接入 ChatGPT,实现私有知识的关键词检索与交互式查询;管理员可统一管控权限,系统自动标注引用来源,便于溯源验证,提升知识复用效率与决策可靠性。
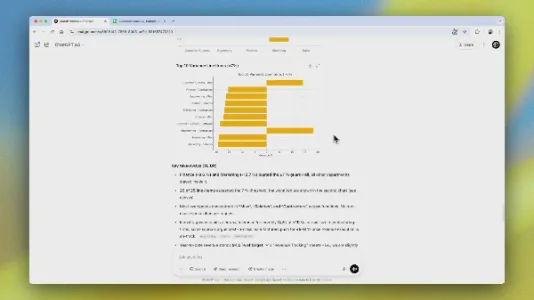
如何使用 OpenAI O3 让 ChatGPT 执行多步骤任务
OpenAI O3 能自主串联多工具,完成端到端的复杂数据任务。以财务月末差异报告为例,用户上传文档并设定需求后,系统自动整合数据、分析差异、生成图表、比对行业基准、撰写报告,并推送至 Slack——全程可追溯,大幅提升分析效率与可信度。
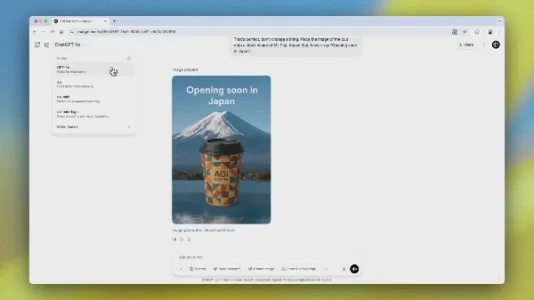
如何通过 GPT-4o 创建符合品牌风格的视觉方案
GPT-4o 可通过自然语言指令,几秒内生成符合品牌调性的视觉方案,覆盖品牌素材、产品图、网站界面等。支持草图转成品,无需设计经验或高价工具,适合快速头脑风暴、可视化表达与低成本方案迭代。

Freepik 图像编辑 AI 助手
Freepik 新推图像编辑 AI 助手,支持用自然语言指令直接修改图片,还能在画布上添加图示与文字备注,让调整更精准、操作更直观,适合设计师快速迭代视觉方案。
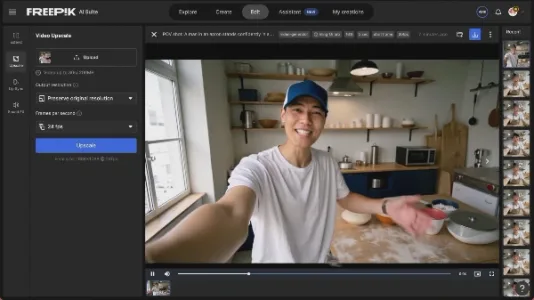
如何通过 Freepik 制作 AI 网红
用 Freepik 搭配 Flux 1.0 生成高细节 AI 网红形象,再通过可灵 1.6 Pro 转为口型同步短视频,支持自定义声音与台词。示例涵盖复古厨房自拍、POV 动态镜头等场景,兼顾人物表情、动作与环境真实感,适合低成本打造专业级 AI 内容。

Runway 学院:如何将 Gen-4 的参考功能和将 3D 素材相互结合
Runway Gen-4 新增 3D 素材整合能力:将 3D 模型渲染为静态图后,结合风格参考图与提示词,可精准控制场景元素、镜头视角与视觉风格,生成高质量定制化视频,大幅提升动态内容的创作自由度与表现力。