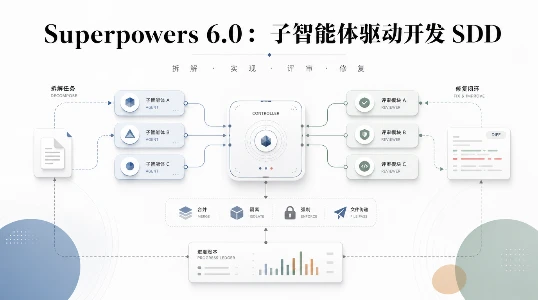
Superpowers 6.0 把 AI 编程评审重写了一遍:子智能体驱动开发到底怎么运作
GitHub 项目 Superpowers 发布 6.0 版本,重写子智能体驱动开发(SDD)方法论,使 AI 编程代码产出速度提升约一倍,token 消耗降低近 50%。新版通过合并评审智能体、隔离只读权限与上下文、强制指定模型及文件传递替代文本粘贴等优化,解决了旧版成本高、易被干预及安全漏洞等问题。该设计思路强调评审环节的重要性,其核心原则可迁移至各类 AI 编程工作流中,有效提升开发效率与质量。

拜耳用 3 层反思循环把 AI 拉进制药生产线:上下文工程和 harness 工程到底在干什么
拜耳制药和 Thoughtworks 在 Martin Fowler 的博客上发表了一篇完整案例,讲他们花了两年多时间把 PRINCE(Preclinical Information Center)从关键词搜索工具演变成多智能体 RAG 系

Claude 自己开机器狗:比人快20 倍,代码量只有十分之一
Anthropic 实验显示,Claude Opus 4.7 已能全程自主控制机器狗完成任务,速度比人类快约 20 倍,代码量仅为其十分之一。这标志着 AI 智能体正从辅助编程迈向物理工具自主操作阶段。但模型在实时闭环精细控制上仍有局限,且当前成果基于低复杂度任务。该进展体现了通用模型 scaling 的副产物效应,预示物理智能体时代早期来临,但距离解决复杂真实场景仍有差距。

微软 Mirage:让世界模型学会“过目不忘”,速度快 10 倍、显存省 55 倍
微软研究院联合多所高校发布 Mirage 模型,通过在扩散模型隐空间直接存储三维记忆,解决了 AI 视频生成中场景一致性差及计算昂贵的问题。该方案摒弃传统 RGB 点云渲染流程,使生成速度提升最高 10.57 倍,显存占用降低 55 倍,且长视频边际成本几乎不增。测试显示其三维与光度一致性优于现有方案,虽暂不支持动态物体记忆,但已开源并适用于机器人仿真等静态场景任务。

JetBrains Junie 正式版:AI 编程 Agent 学会了用调试器断点
JetBrains AI 编程 Agent Junie 正式 GA,在 SWE-Rebench 基准测试中排名第一。其核心优势在于深度集成 IDE 原生工具链,而非模拟替代。主要特性包括:Plan 模式生成结构化计划文档以防跑偏;原生调试器集成支持断点与运行时状态检查;支持异步远程控制长任务;基于项目上下文的交互式代码审查;以及模型自由切换以优化成本。Junie 标志着 AI 编程竞争正从模型能力转向工具集成深度。
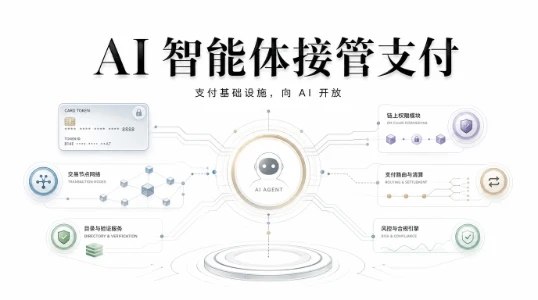
Visa 把支付网络接进了 ChatGPT,AI 智能体终于能自己花钱了
Visa 与 OpenAI 合作将支付网络接入 ChatGPT ,Mastercard 同日发布 Agent Pay for Machines 协议,标志着支付基础设施正式向 AI 智能体开放。Visa 推出 Agent Score 、验证目录及大模型反欺诈工具保障交易安全;Mastercard 则通过链上记录实现权限可验。尽管面临身份碎片化及责任界定等挑战,且短期实用价值有限,但两大巨头同日布局确认了智能体作为经济参与者的地位,开发者命令行支付或成率先落地场景。

Vercel 发布 eve 开源智能体框架:Agent 界的 Next.js 终于来了
Vercel 发布开源智能体框架 eve,采用文件系统优先设计,将 Agent 定义为目录结构以降低理解成本。框架内置持久化会话、沙盒计算、人类审批、安全连接、多渠道部署及可观测性六大生产级能力,解决重复造轮子痛点。eve 目前处于公开预览阶段,框架免费但托管服务收费。该框架标志着 AI Agent 开发正从混乱走向标准化,大幅缩短从 demo 到上线的距离,但需注意 beta 阶段的 API 变动及供应商锁定风险。

SpaceX 4320 亿买下 Cursor:马斯克用一场 IPO 的钱,赌 AI 编程的未来
SpaceX 以 600 亿美元全股票收购 AI 编程工具 Cursor,旨在补齐企业级 AI 产品短板并推广自研 Grok 模型。此举将算力基础设施与产品入口结合,但面临 xAI 团队动荡及文化冲突风险。收购后 Cursor 或调整定价、深度整合 Grok 模型,个人用户权益存变数。交易预计三季度完成,建议开发者关注产品路线图转向及核心人员流失信号,同时该交易也为 AI 编程赛道确立了新估值锚点。

Google 搜索变身全天候智能体:Information Agents 上线,你的数据终于开始替你干活了
Google 推出 Information Agents 功能,面向 AI Ultra 订阅用户开放。该功能将搜索从被动查询转变为主动监测,智能体可 7×24 小时追踪用户需求并推送变化信息。其底层依托 Personal Intelligence 战略,通过整合 Gmail、Photos 等跨应用数据实现个性化推理。尽管存在隐私与准确性挑战,但凭借二十年数据积累,Google 正推动 AI 助手从对话工具向自主代理进化,重塑“信息找人”的交互范式。