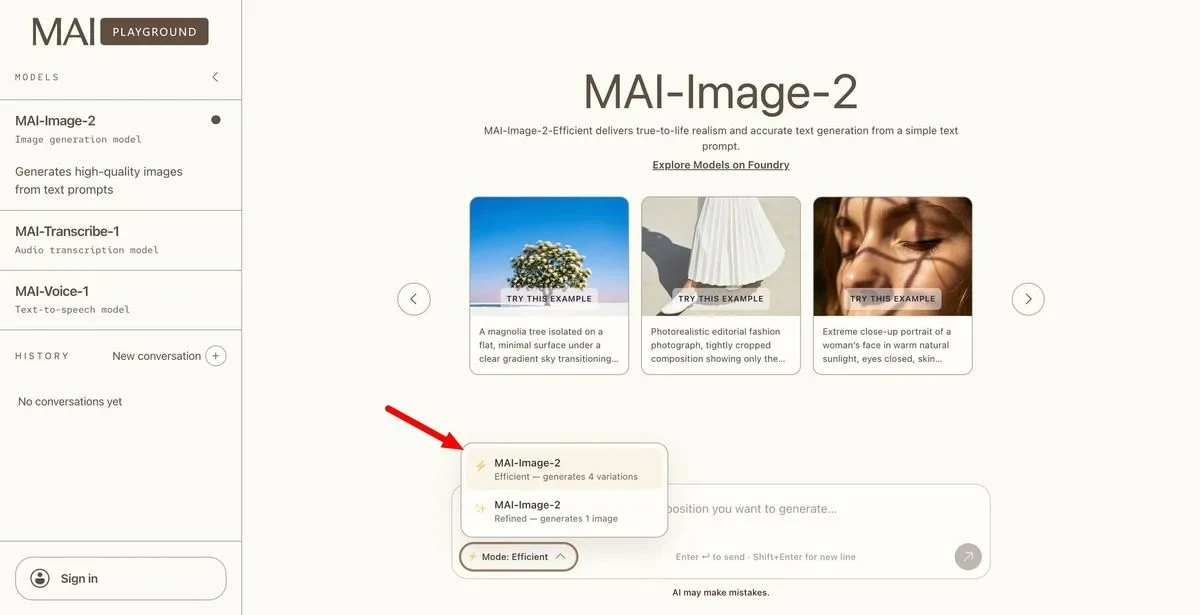
微软发布高速 MAI-Image-2-Efficient 企业版
微软发布 MAI-Image-2-Efficient 图像生成模型,主打低成本与高效率。该模型相较前代提速 22%、效率提升 4 倍,价格降幅约 41%。定位生产级应用,聚焦实时对话、短文本渲染及批处理场景,响应速度较主流竞品快 40%。借此微软形成双层产品矩阵——Efficient 版侧重成本效益,高保真版专注顶级品质,与 Azure+Foundry 平台协同布局企业 AI 生态。 Shutterstock 、 WPP 等已率先采用。

Google Chrome AI 技能上线,帮你保存常用工作流
Google 在 Chrome 中推出“Skills”功能,允许用户将常用 AI 提示词保存为可复用模板,通过斜杠或加号按钮在任意网页一键调用。该功能基于 Gemini 扩展,覆盖食谱查询、购物比价、长文档摘要等高频场景,并同步上线预设模板库。目前面向桌面端 Chrome 用户开放,需登录 Google 账号且语言设置为英语(美国)。
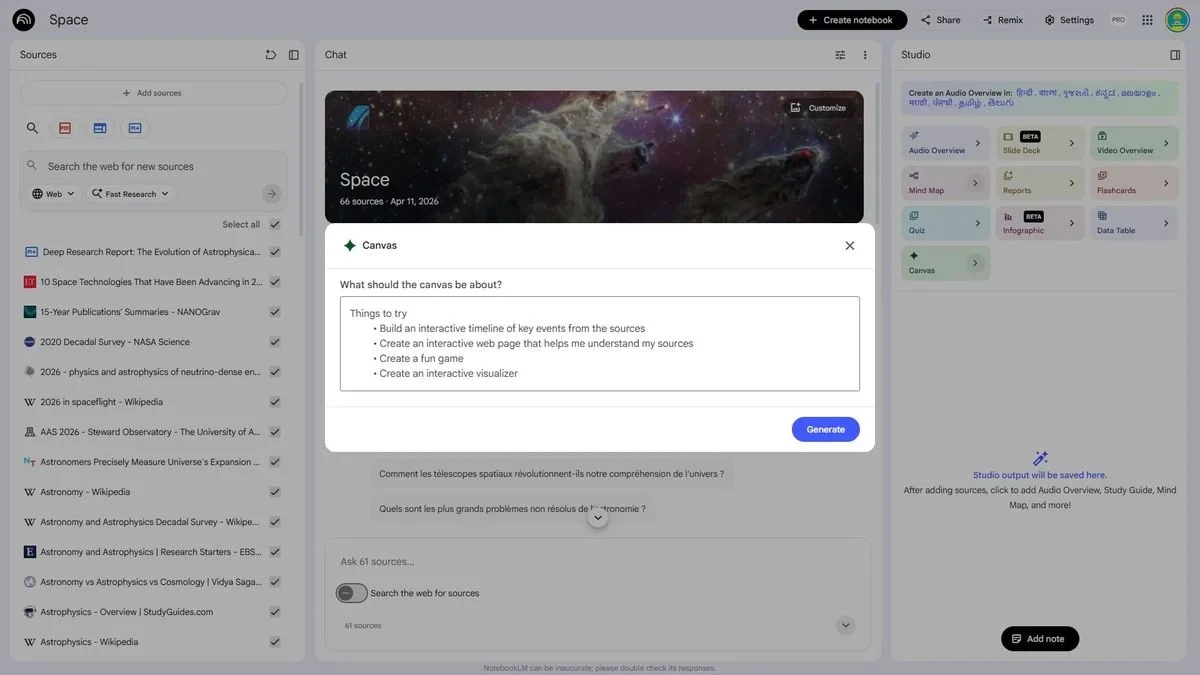
谷歌在 NotebookLM 上测试 Canvas 与 Connectors 功能
Google 正在为 NotebookLM 测试 Canvas 可视化界面与 Connectors 数据接入功能。 Canvas 可将资料源转化为交互式时间线或轻量级应用, Connectors 预计接入 Google Workspace 实现跨服务数据联动。同时新增标签分类功能提升资料管理效率。此番迭代表明 NotebookLM 正从研究助手向结构化创作工作台转型, Google 意在打通知识生产链路,但其开放性与可控性的平衡仍是挑战。
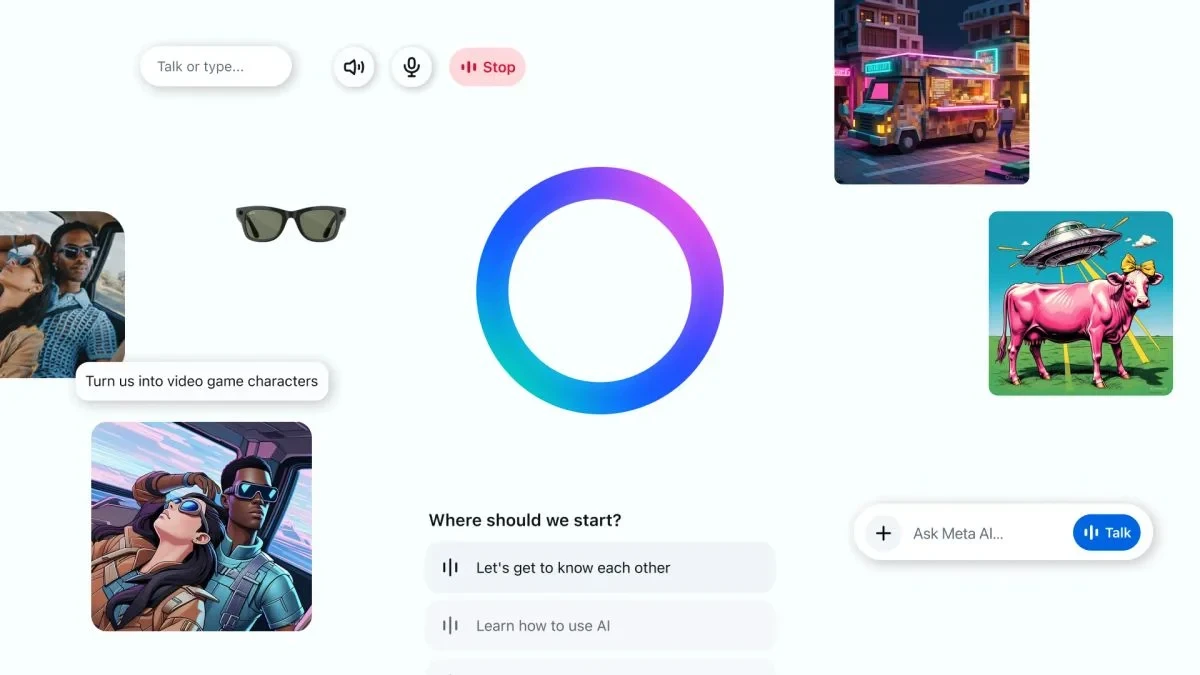
Meta 开始向 Meta AI 智能体推出“沉思模式”
Meta 向所有用户免费开放 Muse Spark 的 Contemplating 模式,采用 16 个智能体并行推理架构,在基准测试中性能对标 Google 和 OpenAI 顶尖模型。 Muse Spark 已位列全球 AI 助手第一梯队,发布后 24 小时内 App Store 排名跃升至第 5 位,全球安装量达 6050 万次。此举旨在以免费策略撬动付费竞品市场,将 AI 助手竞争从“能力对比”转向“生态争夺”。

Google 开发自研桌面智能体与 Cowork 竞争
Google 正在推动 Gemini 向智能体驱动的生产力平台转型。 Gemini Enterprise 新增的 Agent 标签页提供任务执行工作台功能,界面设计与 Claude Cowork 高度相似,设有“Require human review”开关暗示支持人工审批机制。此举表明 Google 正在为与 OpenAI 、 Anthropic 在桌面智能体领域的竞争做准备, Gemini 正从对话式 AI 工具向“数字同事”角色进化。
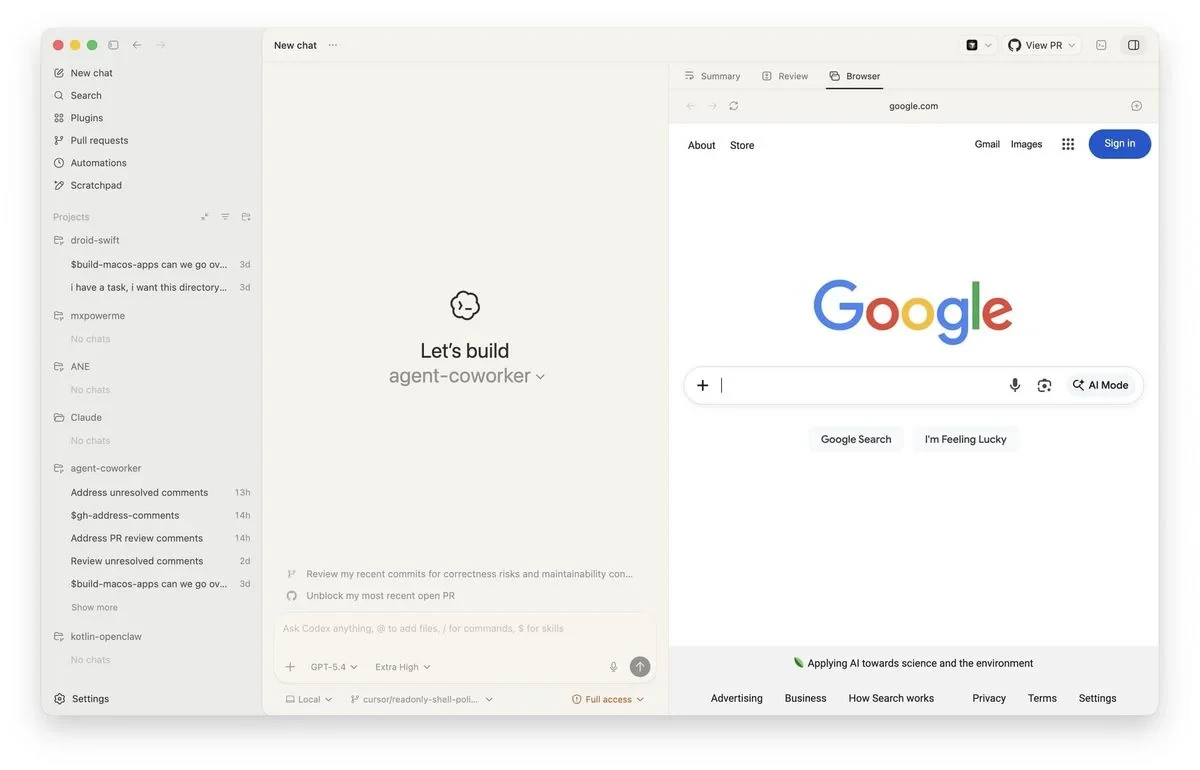
OpenAI 测试 Codex 超级应用的网页浏览功能
OpenAI 正对 Codex 进行重大升级,将其定位为超级应用战略核心产品。新版本引入用户分层配置、 PR 管理、 UI 预览与内联评论等功能,并支持并行任务处理, Codex 正从编程工具演变为覆盖规划、构建、审查、发布的全周期开发环境。此举旨在与 Anthropic 的 Claude Code 等竞品竞争,最终目标是让 ChatGPT 与 Atlas 浏览器在桌面端合二为一,成为统一超级应用。

微软正在开发另一个 OpenClaw 类智能体
微软正测试将开源本地智能体 OpenClaw 的核心功能整合至 Microsoft 365 Copilot 平台,面向企业客户强化安全控制。新产品定位为“持续运行”版 Copilot ,能随时执行跨长时间周期的多步骤任务,计划于 6 月 Microsoft Build 大会亮相。此举标志着微软智能体产品线从云端向本地延伸,与已发布的 Copilot Cowork 、 Copilot Tasks 形成互补。分析认为,本地化运行不仅关乎安全,更意味着更低延迟和更强离线能力,但如何在隐私风险与用户体验间取得平衡将是关键挑战。

传苹果正测试四款智能眼镜设计
Apple 正在测试四款智能眼镜原型,计划最快 2027 年面市。与此前 Vision Pro 的混合现实路线不同,这款眼镜不配备显示屏,定位更接近 Meta 与雷朋合作产品,主打拍照、录像、通话、音乐播放及 Siri 智能交互等功能。此举被视为 Apple 在无显示屏智能眼镜赛道上的精准卡位,避开尚不成熟的显示技术,转而聚焦音频、语音和影像等基础交互能力,试图在智能眼镜成为下一代交互载体的趋势中抢占先机。

Nano Banana 2 :融合 Pro 级性能,闪电般极速
Google DeepMind 发布 Nano Banana 2 图像生成模型,将专业级能力与极速响应合二为一。核心升级包括继承 Pro 版的世界知识与文本渲染技术,同时具备闪电般的生成速度。技术亮点涵盖精准对象渲染、信息图表与数据可视化、主体一致性支持 5 角色 14 对象、复杂指令理解及 512 像素至 4K 分辨率输出。该模型现已集成至 Gemini 、 Google 搜索等多平台,并强化 SynthID 溯源技术。这标志着生成式 AI 图像领域专业工具的加速普惠。