Google 将大范围推广 Gemini 技能与 AI Studio
Google 正将“技能模块”功能扩展至 AI Studio 等更多产品。该功能是可复用指令集,可引导 Gemini 稳定输出并实现自动化工作流。此前仅企业版可用,现普通用户版本也将跟进,且桌面应用已在规划中。若在消费版、企业版和 AI Studio 三端实现覆盖, Google 将形成统一定制层,缩小与竞争对手差距。
Anthropic 为 Claude 移动应用开发全天候托管智能体
Anthropic 正推进 Claude 智能体的移动端部署, iOS 应用已出现相关功能标记,意味其网页端托管智能体服务将扩展至消费级移动应用。此举将使普通用户获得常驻式智能体服务,可调用记忆、偏好及关联工具。技术层面,代码标记出现在 iOS 生产版本而非实验分支,显示功能已趋成熟。竞争层面, Kimi 、 Minimax 、 Manus 等已先行布局, Anthropic 入局表明 AI 行业竞争正从模型能力延伸至智能体体验层,智能体正成为平台标配能力。
Anthropic 为 Claude 平台 API 用户推出智能顾问工具
Anthropic 在 Claude 平台推出顾问工具,让 Opus 模型担任“顾问”,配合 Sonnet 或 Haiku 作为“执行器”。执行器独立处理日常任务,遇复杂决策时自动升级求助,实现高级推理与成本控制的平衡。测试数据显示, Haiku 配合 Opus 顾问后性能提升一倍以上,成本显著低于单独运行 Sonnet 。这一“小模型执行+大模型顾问”模式正成为智能体开发的主流架构。
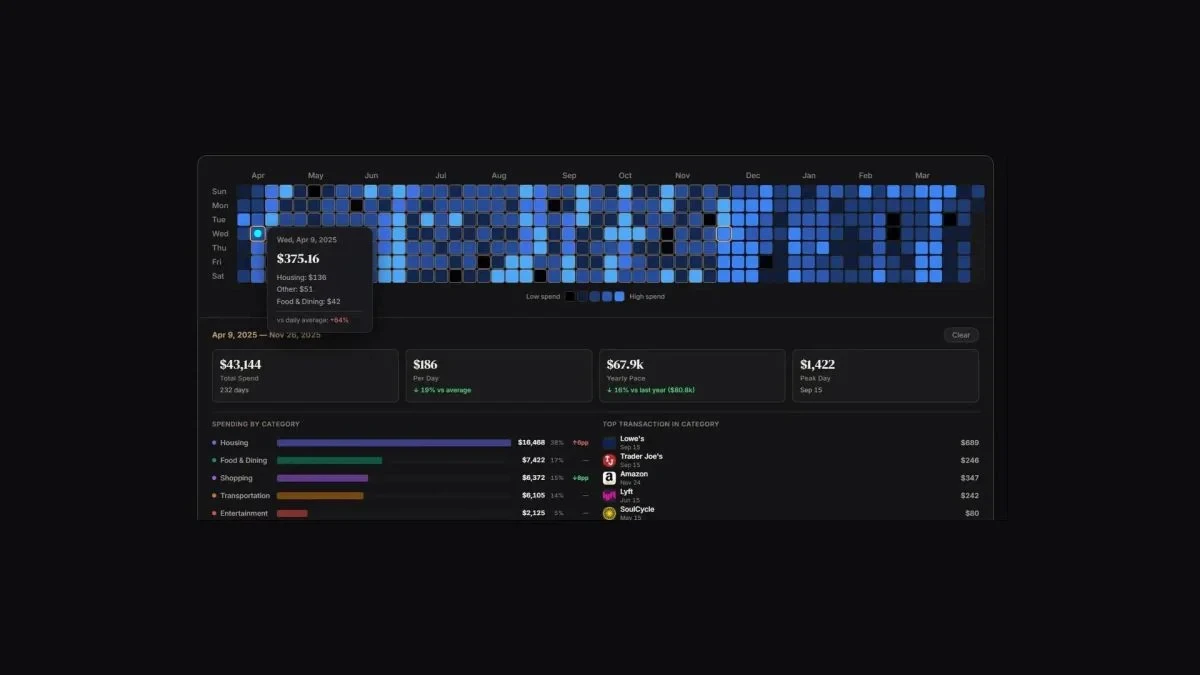
Perplexity 推出个人理财功能,由 Plaid 提供支持
Perplexity 深化与 Plaid 合作,推出个人财务管理功能。用户可关联支票、储蓄、信用卡、贷款及投资账户,获得支出分析、负债追踪、净资产计算等财务洞察。产品定位为 AI 个人财务分析师,不涉及资金转移。 Pro 和 Max 用户可解锁进阶智能体功能。安全信任边界成为产品普及的关键挑战。
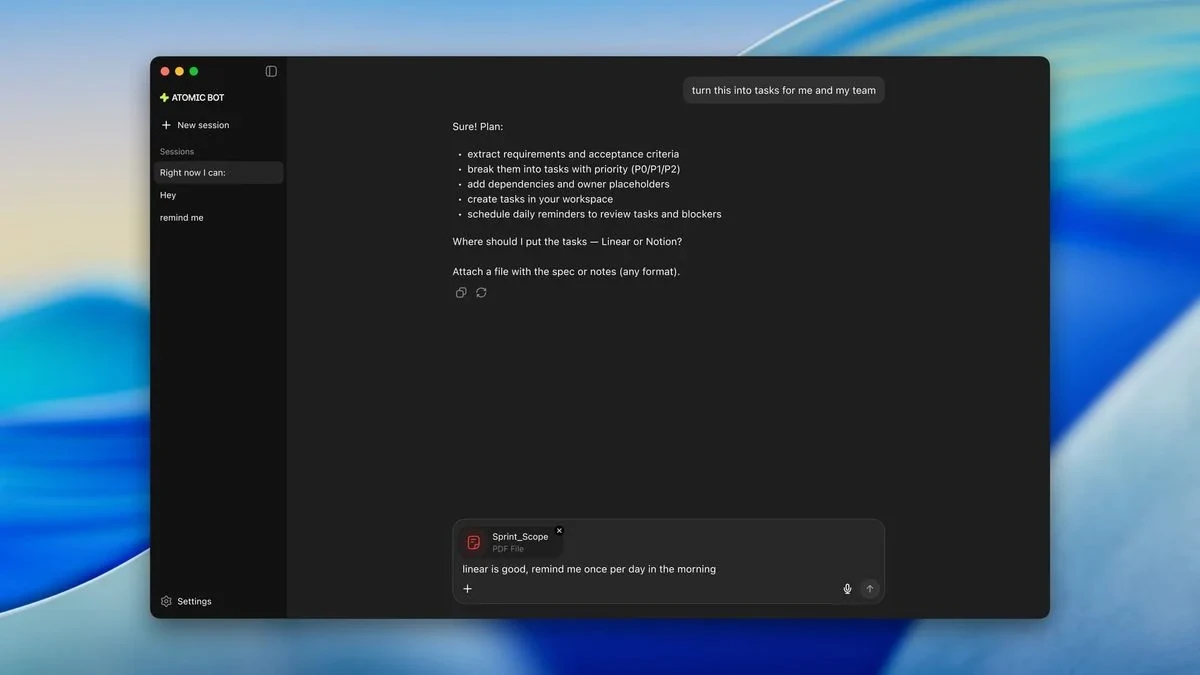
Atomic Bot 现可在电脑上运行本地 AI 模型
Atomic Bot 现已支持本地运行,通过 Ollama 集成 Llama 、 Gemma 、 Qwen 等开源模型,实现完全离线推理。其核心优势在于数据隐私保护和使用成本控制——用户数据不离开设备、无按条计费、无需注册账户。配置门槛相对亲民, 7B 模型仅需 16GB 内存即可运行,同时保留邮件、日历、浏览器自动化及跨平台消息等完整功能。基于 OpenClaw 框架开源构建,跨平台桌面应用简化部署。随着 AI 助手掌握高敏感个人信息,本地化运行将从开发者偏好演变为终端用户的刚性需求。

Telegram 新增 AI 文本编辑器及升级版投票功能
Telegram 面向全部用户推出 AI 文本编辑器,由自研 Cocoon AI 驱动,集成语法纠正、多语言翻译及七种预设风格转换,并承诺不保留用户数据。投票系统同步升级,新增图片、音频、定位等附件功能。此次更新围绕“生产力、隐私、创意”三大维度展开, AI 能力正成为即时通讯应用的标配。
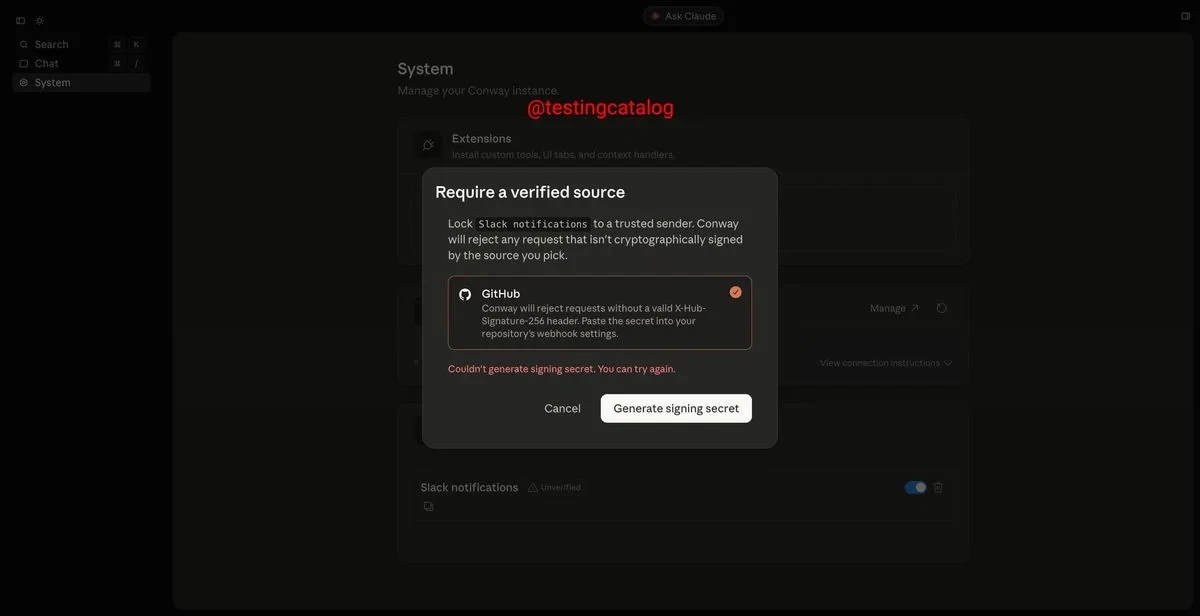
Anthropic 据传正在测试 24/7 全天候 AI 智能体服务
Anthropic 推出代号 Conway 的智能体项目,主打全天候托管服务,集成 Webhook 接口、加密签名验证、扩展组件和浏览器操作等企业级功能。该项目定位为连接 Claude Code 、 Cowork 等产品的“粘合剂”,构建持续运行的事件驱动智能工作空间。设计逻辑强调安全性、可审计性和系统自动化通信,目标用户已从个人开发者转向企业客户。这也折射出 AI 行业从个人生产力工具向团队托管式智能体基础设施的范式转移趋势。

Anthropic 推出 Claude Mythos ,剑指网络安全研究
Anthropic 发布专用于网络安全研究的 AI 模型 Claude Mythic Preview ,具备自主发现零日漏洞并生成利用代码的能力,已在 OpenBSD 、 FFmpeg 和 Linux 内核中发现严重安全问题。该模型目前仅向 Project Glasswing 计划合作方开放,提供总计 1 亿美元使用额度。此举标志着 AI 安全研究从被动防御向主动猎取的范式转变,通过将高风险能力锁定在可控生态内形成双重约束。
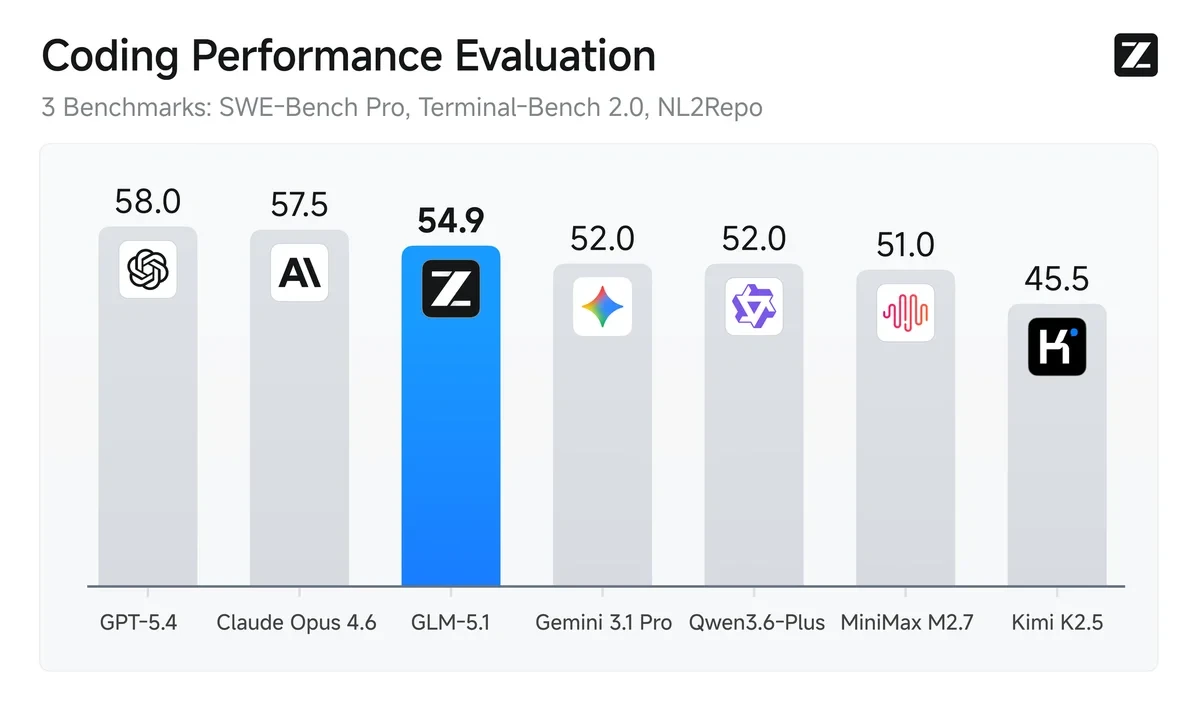
智谱 AI 发布开源 GLM-5.1 编程模型
智谱 AI 发布 GLM-5.1 编程模型,专为编程和智能体工程设计,可持续运行 8 小时完成规划、执行、测试、修复等全流程任务。基准测试表现亮眼, SWE-Bench Pro 获 58.4 分,超越 GPT-5.4 等竞品。具备 20 万 token 上下文窗口等技术优势,现已面向开发者开放。此举标志着智谱 AI 在编程和智能体基础设施领域迈出关键一步。