可灵向部分用户开放了自定义模型(Custom Models)功能。用户需要上传 10 到 30 个同一人物的不同视频,每个视频的时长至少为 10 秒。可灵将基于这些视频训练出具有一致性的视频角色。这一过程的思路类似于 AI 绘画中的 LoRA 模型,是 AI 视频角色一致性方面的一项重大突破。
以下是 AIGC 达人Halim Alrasihi 通过 Midjourney 和可灵自定义模型功能训练视频角色模型并生成视频的详细过程。
操作过程

可灵的自定义模型能够捕捉视频中人物的重要外貌特征。可以上传真实的人物视频,也可以通过 Midjourney 的角色参考(--cref) 功能生成同一个人物的多张照片。
将角色图像上传到可灵,制作 10 个以角色脸部为中心的视频。尽可能使用不同的背景、服饰、表情,但视频尽可能保持简单。完成后提交给可灵,生成角色视频模型。
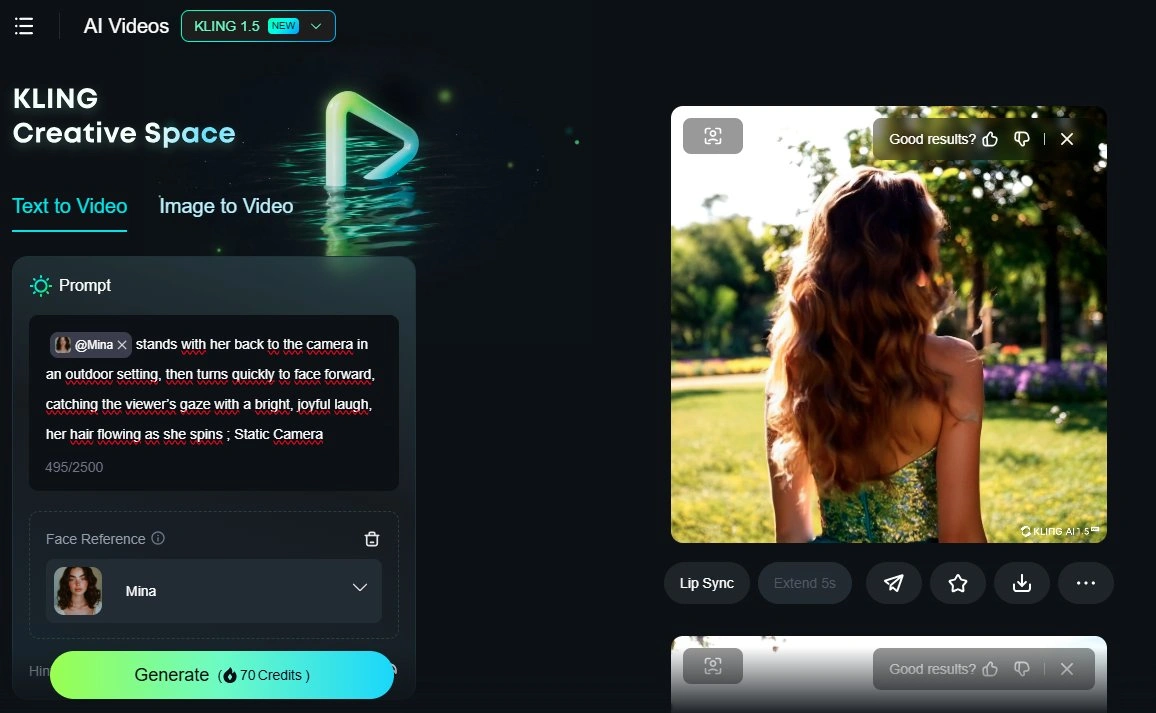
完成之后就可以通过文字生成视频了。只要在提示词中加入之前为角色模型起的名字即可。以下是通过自定义模型生成的人物视频。
视频提示词:[@ character] stands with her back to the camera in an outdoor setting, then turns quickly to face forward, catching the viewer’s gaze with a bright, joyful laugh, her hair flowing as she spins.[@角色] 背对着镜头站在户外环境中,随后迅速转身面对前方,以明亮而愉快的笑声吸引观众的目光,头发在旋转时随风飘扬。

