你还在用三个模型分别处理视频、音频和文字?
NVIDIA 在 4 月 28 日开源了 Nemotron 3 Nano Omni,用一个模型同时处理所有模态,且不损失效率。
三个模型各自为政,这事有多贵
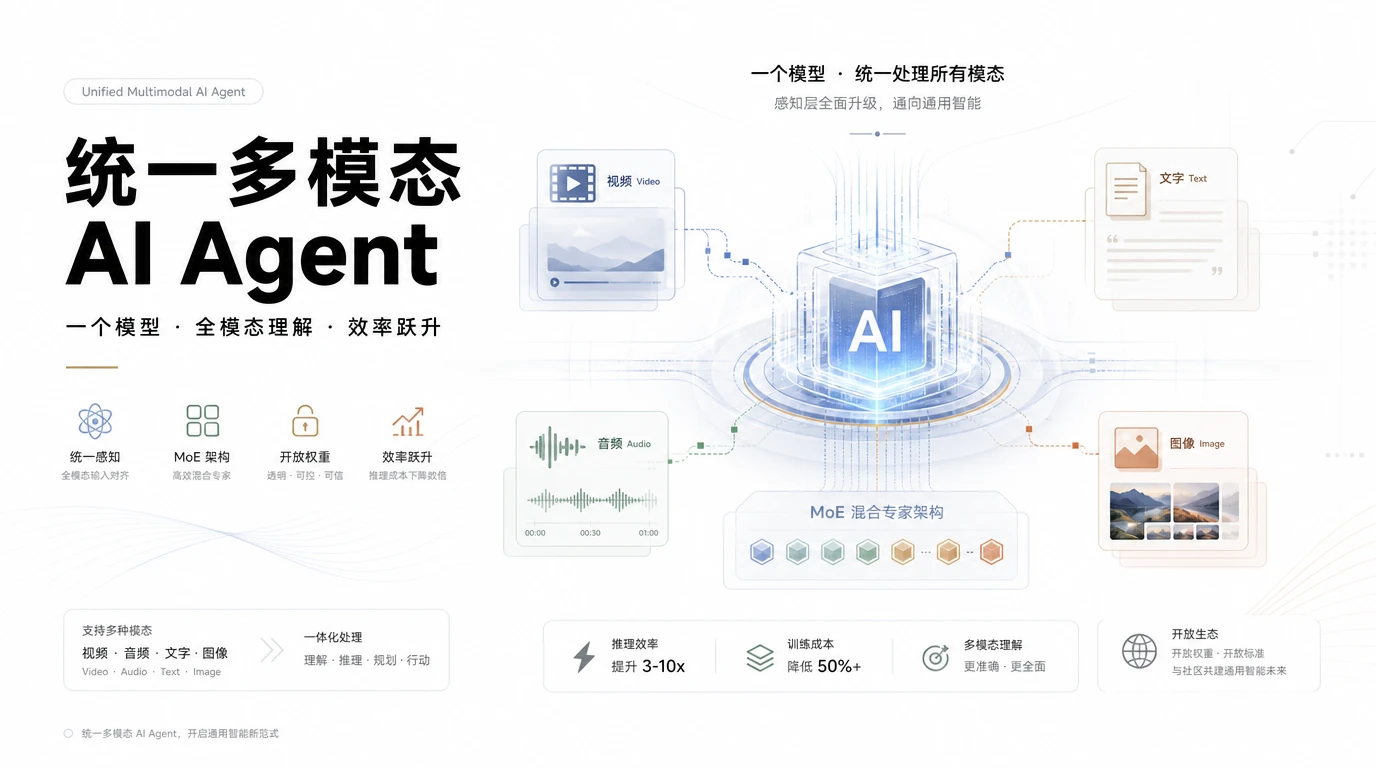
AI Agent 当下最主流的架构是“拼接式”:视觉模型处理图片、视频,语言模型处理文字,语音模型处理音频。三套系统串在一起工作,能用,但也存在一堆问题。
每次信息在模型之间传递,都要经历一次“编码->传输->解码”的过程。以一个客服 Agent 举例:用户发来一段屏幕录像加一段语音,Agent 要先用视觉模型分析录像,再用语音模型转写音频,最后把两个结果塞给语言模型做综合判断。每多一次跨模态传递,就多一次延迟、多一层上下文损失,还多烧一l轮 Token。
更关键的问题是成本。三个模型意味着三份显存、三份计算资源、三份维护成本。如果要做高并发,比如同时处理 100 个视频流,光硬件成本就够让大多数团队重新考虑要不要做这个功能。
所以过去一年,行业里冒出来很多“统一多模态”的尝试,方向都是对的。但大多数方案是拿一个超大的视觉语言模型硬啃所有模态,确实能处理,但做不到又快又便宜。
Nemotron 3 Nano Omni 的路线
Nemotron 3 Nano Omni 走的是混合专家(MoE)路线。
具体来说,这是一个 30B 参数、激活参数只有 3B 的模型。30B-A3B 这个比例的意思是:模型总参数 300 亿,但每次推理只激活 30 亿参数参与计算。就像一个公司有 300 个员工,但每个项目只调动最相关的 3 个人。
这带来的直接好处是:内存占用和计算量大幅下降,推理速度大幅提升。官方数字是对比同档次其他开源多模态模型,吞吐量最高提升 9 倍。视频推理场景下,单位时间内处理的视频量是竞品的 9 倍。多文档推理场景下,提升 7.4 倍。
这不是纸面数字,是生产级别的对比。
架构上,它把 Mamba 序列模型和 Transformer 层叠在一起用:Mamba 负责快速过滤长上下文里无关的信息,Transformer 负责精确的推理计算。视频处理用了 3D 卷积来捕捉帧与帧之间的运动关系,配合一个叫 Efficient Video Sampling 的层,把数百帧视频压缩成几十个精心挑选的视觉 Token 直接送进语言模型。
语言模型核心用的是 NVIDIA 自己的 Nemotron 系列文本 decoder,在此基础上绑定了音频编码器(Parakeet 家族)和视觉编码器(C-RADIOv4-H)。视觉编码器特别针对高分辨率文档做了优化,能在 OCR 任务里保持小字清晰度,这是很多通用视觉模型翻车的场景。
这套架构的实际效果是:单次推理循环里,模型同时看到文字、图像、视频帧、音频频谱,不需要分别调用三个模型,也不需要各自输出的特征做对齐融合。一切都在同一个 Token 生成流里完成。
为什么是 Agent 场景的最大受益者
这个模型发布的时候,新闻稿里反复提到一个词:Agentic AI。
仔细想了想,为什么 Agent 场景这么适合这个模型。
现在 Agent 的标准工作流是:感知->规划->执行三步。感知层负责把世界的各种信号转成语言模型能处理的信号,执行层负责调用工具或操作界面。如果感知层本身是多模态割裂的,每多一次模态切换,Agent 对当前环境状态的“把握感”就少一分。
H Company 基于这个模型做了一版电脑使用 Agent,接收 1920×1080 的原生屏幕截图做视觉推理。他们在 OSWorld 基准测试里跑了一下,复杂图形界面导航准确率相对之前有明显提升。关键是延迟:处理一张全高清截图的时间从秒级降到了可以接受的水平。
这就是“统一感知”的实际价值!不是“听起来更优雅”,而是“真的能用、够快”。
另一个典型场景是文档智能。Agent 在金融或合规场景里经常要同时读 PDF、扫描件、截图、电子表格、图表。以前这些需要不同的模型分别处理,现在一个模型可以同时吃进所有格式,并且保持视觉结构和文字内容的关联推理。
客服场景也是。用户发来一张产品截图、附一段语音描述问题、手写一张草图示意。三个模态一次进入推理循环,Agent 一次输出判断结果,而不是“先处理图,再处理音频,再合并推理”的三跳架构。
开放权重这件事本身就有意思
大多数商业多模态模型是封闭的,要调用 API,按 Token 计费。
Nemotron 3 Nano Omni 完全开放权重,训练数据集开放,训练配方也开放。权重在 Hugging Face 上可以直接下载,定制的后训练流程在 GitHub 上有完整配方。
和竞品比,位置在哪里
其实多模态模型早已是红海。GPT-4o、Gemini、Claude 都早就支持了多模态输入,开源模型 LLaVA、Qwen-VL 也在追赶。
但 Nemotron 3 Nano Omni 的定位比较独特。它的目标不是让人类直接使用,而是嵌入到更大的 Agent 系统里做感知层。和它配套的还有 Nemotron 3 Super(高频执行)和 Nemotron 3 Ultra(复杂规划),三个模型构成一个分层 Agent 架构。Ultra 做复杂推理规划,Super 做日常执行,Nano Omni 做多模态感知。
这种分层设计的好处是:每个层都可以选最适合该任务的模型,而不是用一个大模型硬扛所有工作。专业的事交给专业的模型,成本和延迟都更低。
在 Hugging Face 开放权重列表里,这个模型在 6 个基准榜单上排在第一,包括文档智能(MMlongbench-Doc、OCRBenchV2)、视频理解(WorldSense、DailyOmni)、音频理解(VoiceBench)。
一点技术细节,帮你判断要不要用
- 上下文长度 262K token,约等于可以一次读进去 20 万汉字的文本量,或者大约两小时的视频帧压缩后的总长度。
- 激活参数 3B,用消费级 GPU 跑 FP8 量化版本,显存占用大概 6-7GB,RTX 3090 级别可以本地跑起来。这在 30B 级别的模型里属于非常轻量的推理成本。
- 量化方案除了 FP8,还有 NVFP4(4 位浮点),这是 NVIDIA 自家的硬件级量化格式,在 Blackwell 架构 GPU 上效率最高。如果有 H100 或 H200 集群,NVFP4 版本的性价比会非常高。
- 音频处理不只是语音识别,官方支持音乐理解、视频里的人声情感分析这类任务。用 Parakeet 编码器配合专门的音频微调数据实现的,不是简单的语音转文字。
- 视频采样策略是推理时动态的,模型会根据内容复杂度自动决定压缩多少帧,不是一个固定的下采样率。这意味着静态场景不会浪费 token,动态场景也不会因为过度压缩而丢失关键信息。
三个模型拼接是低效的,一个超级大模型是昂贵的,一个 MoE 混合架构才是兼顾效率和能力的正解。这不只是 NVIDIA 的技术选择,更是整个行业走向生产级 Agent 架构的信号。当多模态感知从“能力展示”变成“智能体刚需”,谁能提供更便宜的感知层,谁就能在 Agent 大规模落地的浪潮里拿到一张船票。


