角色视频合成的目的是制作看起来真实的动画角色视频,这些角色可以在生动的场景中活动。传统的 3D 模型通常需要从多个角度拍摄来训练,这让它们很难快速创建不同的角色。最近的一些 2D 方法改善了这一点,使用了预训练的扩散模型,但在处理姿势变化和场景互动方面仍有困难。
为了解决这些问题,阿里提出了一个新的模型:MIMO。这个模型可以根据简单的用户输入生成可控的角色视频,能够灵活处理各种角色,适应新的 3D 动作,并在现实场景中实现互动。
MIMO 的核心思想是将 2D 视频转化为紧凑的 3D 形式。具体来说,就是用单镜头深度估计技术把 2D 图像提升为3D,并把视频分解为三个主要部分:主要人物、背景场景和漂浮的遮挡物。这些部分转化为控制信号,帮助生成视频。这种分解方法使得用户可以灵活控制视频内容,表现空间运动,也让合成过程更好地与场景互动。
实验结果显示,这种方法在效果和稳定性上都表现得很好。
核心思想

模型能够把你提供的角色图片、动作描述和场景图片,这三种信息转化为内部的指令,然后组合起来,生成一个符合要求的动画视频。这样你就可以轻松控制角色在特定场景中的动作和表现,无需复杂的操作。
实现方法
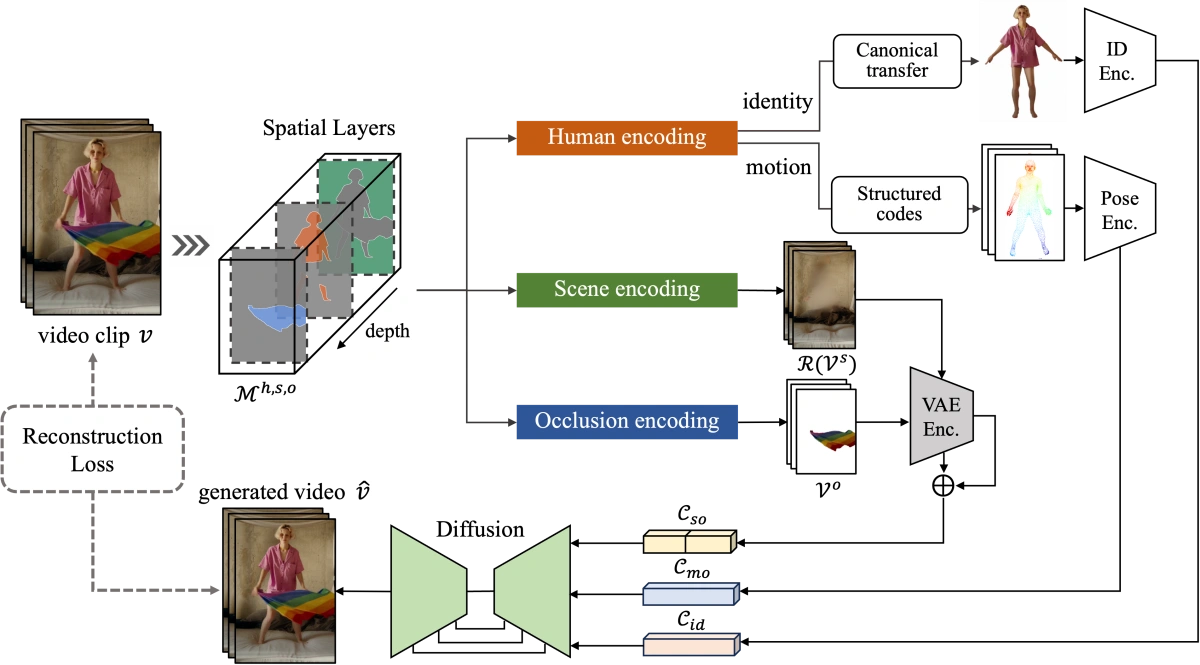
MIMO 会将一个视频分解成几个部分,然后再重新组合生成新的、相似的视频。具体步骤如下:
将视频分成三部分
- 主要人物(Main Human): 视频中的主要角色,比如一个人在跳舞。
- 背景场景(Underlying Scene): 人物所在的环境,比如舞台或公园。
- 漂浮的遮挡物(Floating Occlusion): 视频中可能挡住视线的物体,比如飘落的叶子或飞舞的纸屑。
深入处理主要人物
- 身份属性(Identity):识别出这个人物是谁,比如穿什么衣服、长什么样子。
- 动作属性(Motion):记录这个人物在视频中的动作,比如跳跃、挥手。
这些信息分别被转换成三个内部代码
- 身份代码(Cid):记录人物的外观和身份信息。
- 动作代码(Cmo):记录人物的动作和运动方式。
- 处理背景和遮挡物:场景代码(Cso):背景和遮挡物的信息被一起处理,转换成一个综合的内部代码,表示整个场景的布局和细节。
重建视频
这些内部代码(身份代码、动作代码和场景代码)被输入到一个“扩散解码器”(diffusion-based decoder),这个解码器根据这些条件重新生成视频。
为什么要这么做
通过将视频分解成这些部分并分别处理,可以更好地控制和调整每个部分。例如,你可以更改人物的动作,换一个背景,或者添加更多的遮挡物,而不需要重新制作整个视频。这使得视频生成和编辑变得更加灵活和高效。
效果演示
任意角色控制

通过单张输入图像制作人类、卡通或拟人角色的动画
新颖的3D动作控制
从现实视频中提取复杂动作
来自数据库的空间3D动作
交互式场景控制
复杂的现实场景,包含物体交互和遮挡效果
MIMO 项目地址