作者:Yunmie Kim (金允美),StoryTribe 创始人
翻译:零重力瓦力
自从两个月前辞去全职工作以来,我深入创业社区,并在为 StoryTribe 筹集资金时与众多风投接触。一个经常被提及的问题是:"AI可以生成分镜。为什么有人会选择 StoryTribe?"
以下是 AI 永远无法与 StoryTribe 竞争的原因

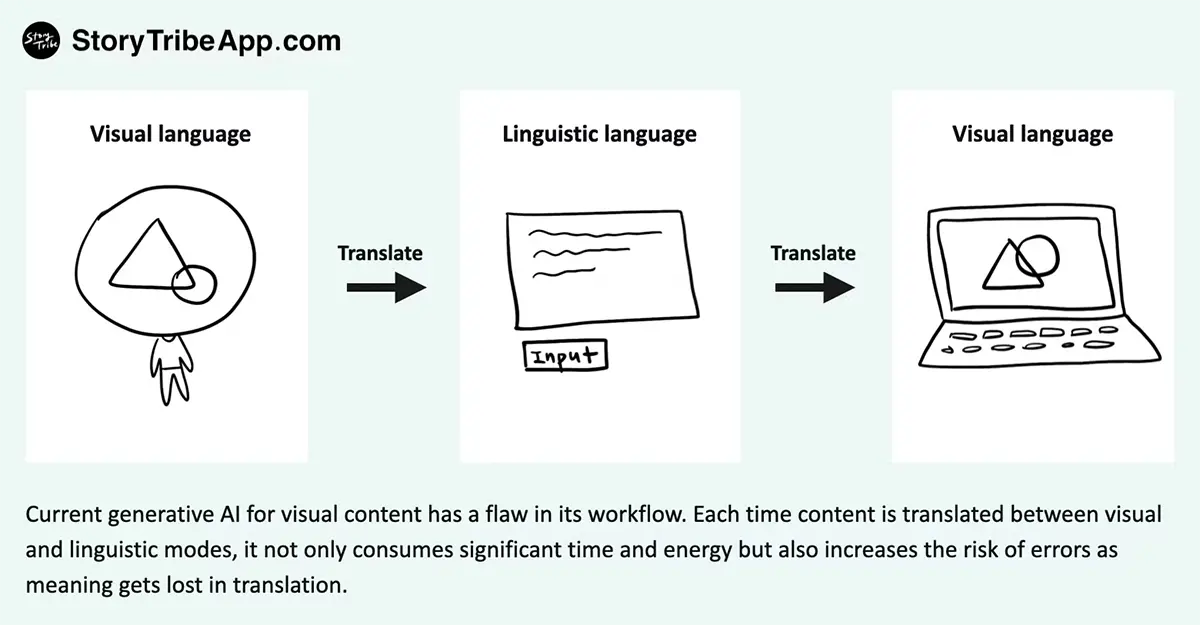
当前用于生成视觉内容的 AI 在工作流程上存在一些缺陷。
任何 AI 生成的内容都需要人类进行输入,我称之为"人机交流",因为AI无法读懂你的想法。除非我们将来某天决定直接将大脑连接电脑 (这本身就是一个有趣的问题),否则人类总是需要将思想转化为 AI 的指令。
但当前用于生成视觉内容的 AI 在工作流程上存在一些缺陷。让我简单解释一下。
在生成分镜中的场景时,你的大脑首先会形成一个想法或概念。这很像你的梦境,往往时难以用语言描述的模糊思想和感受。由于我们的大脑处理视觉信息的速度是文字的 600 倍,这些想法和概念通常会在变成文字之前自动地转化为图像。如果,要将它们转化为文字需要更多的时间和精力。
在为 AI 写提示词时,你需要用文字描述你的想法。然后 AI 根据自己对你提示词的理解生成图像。这种转译不可避免地会受到源自全球数据的泛化以及普遍理解的影响。但我们不仅仅有几个泛化的想法,我们有无数独特的创意,而 AI 可能会错过这些。
所以,在转译过程中信息通常会有所损失,这是很正常的。即使在人与人之间的交流中,我们也面临类似的挑战。你说了什么,而对方根据他们过去的经历来解释,猜测你的意思。误解的可能性很高,奥格尔维定律就捕捉到了这一点:"沟通通常会失败,成功往往是意外"
要获得更好的结果,你需要的是交流而不是单向沟通。要让 AI 通过询问澄清信息,你可以随时完善细节,提供更具体的指示。但当前系统不允许这种来回交流或"编辑"。每次你提供后续提示时,AI 都会将其视为新指令,重新生成整个图像,重置所有已经建立的细节。
让我们总结一下,当前用于生成视觉内容的 AI 在工作流程上存在以下几个缺陷:
- 语言模式转换: AI 使用语言提示来生成视觉内容,这意味着你的视觉想法必须首先转换成文字,可能导致意义和细节的丢失。
- 独特想法的丢失: AI 的输出基于从全球数据源得出的泛化、普遍信息。这往往会忽视人类可能有的更具创意和独特的想法。
- 缺乏对话: 当前系统不允许来回交流。你无法像在真实对话中那样在生成过程中澄清或完善细节。
一个示例场景
让我们用一个简单的例子来可视化上述工作流程。想象你脑海中有下面这个图像,你想将其纳入你的分镜。我故意选择了一个没有任何角色,非常简单的图案来说明问题。
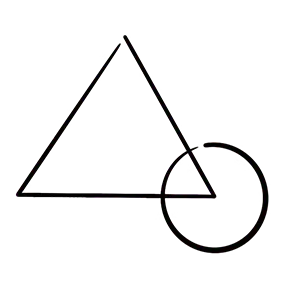
第一步是将这个视觉想法转换成语言描述。所以你可能会以 "一个草图风格的略微重叠的三角形和圆形" 作为 AI 提示词。
下面的图像是我用 DALL-E 尝试后得到的结果。
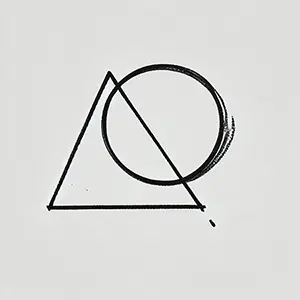
它接近了,但不完全是我想要的。在这个工作流程中,我无法编辑或移动任何元素,所以我需要用新的描述再次尝试。下一个提示可能是类似这样的:"三角形比圆形大得多,位于左侧,圆形在右侧,与三角形的右下角略微重叠。"
请注意,想出这些额外的细节并用文字描述会花费大量的精力、时间和脑力。如果我能简单地编辑元素:调整三角形和圆形的大小,调整它们的位置,直接进行更改而不需要重写整个提示,那会容易得多。
尽管如此,我尝试用这个详细的描述在 DALL-E 上进行了第二次和第三次尝试,得到了下面的图像。接下来的 10 次尝试也有些相似,但并没有更接近目标,所以我放弃了。
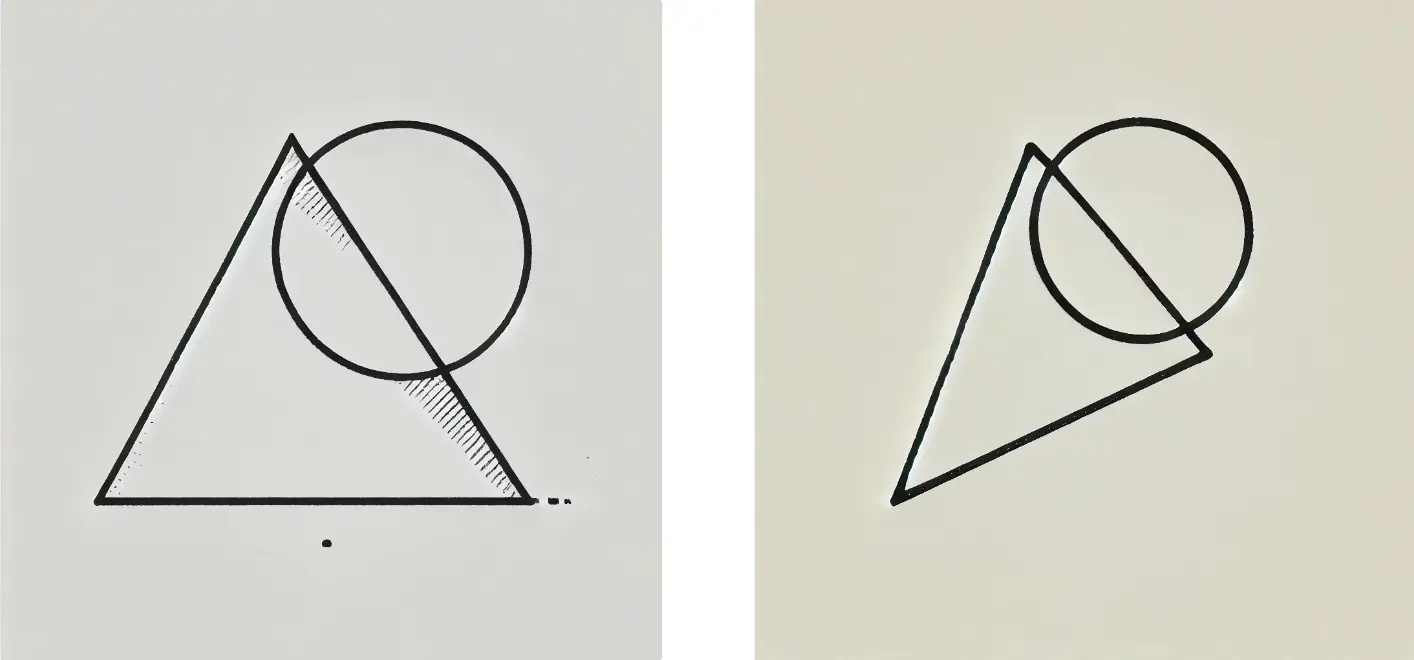
这只是一个简单的例子。现在,想象一下生成一个有角色、道具和背景的真实分镜。那将涉及姿势、情感、动作、位置、比例、角度、构图等元素。复杂度会急剧增加。

这是电影《寄生虫》中标志性场景的分镜,由导演奉俊昊亲自绘制。要用AI生成这个场景,你需要详细描述它。比如 "基泰回头越过肩膀看,表情惊讶,手里拿着一张有血迹的皱巴巴的纸巾。画面在胸部水平截断..."。想出这种程度的描述需要大量精力,而且会产生很多误解。
下面是 DALL-E 根据这个提示生成的图像。它接近了,但许多细节都不对。要使其正确,我们需要完善诸如男子的头部角度、面部表情的微妙细节、手和手臂的位置等细节。现在想象一下必须用文字描述每一个变化。这可能需要数百个提示。我希望你能明白我的观点。

我确信随着技术的成熟,AI在处理细节方面会逐渐改进。特别是考虑到当前的发展速度,,AI很快就能在几个提示后生成更准确的图像,而不是像今天这样需要数百次尝试。
但问题在于达到最终输出所花费的时间和精力。这个过程涉及两次模式转换:首先,将视觉想法转换为语言,这需要人类付出大量努力,然后计算机再将这些词语转换回视觉,这个过程可能会造成大量得误解,信息在 “转换” 过程中丢失了。
更好的体验是什么样的?
要创造更好的体验,应该尽量减少语言模式切换的需求(在视觉和语言模式之间)。此外,画面中的元素应该是可调整的,让用户有更多控制权来创造独特的视觉效果,而不是完全依赖于泛化的 AI 输出。这个过程应该更像是一场对话,而不是单向交流。在这种对话中,用户可以通过不断完善并将反馈传达给 AI 进行迭代,使每次互动都能进一步增强和个性化他们的视觉效果。
消除这种语言模式切换的最佳方式是绘画。当你脑中有一个图像时,你只需简单地勾勒出来,无需拼写,然后让 AI 进一步完善。然后,你可以通过在现有视觉输出上添加更多绘制的细节,与 AI 进行视觉对话,在这个过程中给 AI 更清晰的指导。
问题是大多数人对自己的绘画技能缺乏信心。当我说"绘画"时,我不是指复杂的、专家级的插图,只是简单的涂鸦风格的草图或基本的铅笔画,我相信几乎每个人都能做到。问题在于我们中的许多人在成长过程中感到自己在这方面不够好。人们对自己的火柴人画感到尴尬,因此不愿意画更多。结果,他们因停止练习而错过了提高的机会。
StoryTribe 如何做到与众不同?

我对StoryTribe的愿景就是解决这个问题,让人们意识到他们能够画画。我们将提供现成的元素,用户可以轻松组合,并使用户更容易添加自己的个人风格,这样他们就可以创作出自己的绘画。
这种方法鼓励人们画更多,因为有了资源库的一些帮助,创作出令人满意的绘画变得更容易。它也使这个过程更有乐趣,当他们在其中找到乐趣时,自然会更经常画画。随着时间的推移,他们会在不知不觉中进步。这正是我学习绘画的方式 — 我通过简单地去做,并享受这个过程而得到提高。
我希望 StoryTribe 能激发每个人画得更多,让人们轻松愉快地在画布上实现他们的想法。画画应该像跑步或听音乐一样自然。它是每个人的基本技能,每个人都应该从中受益。然而,由于某些原因,这并不是现实,我想改变这种状况。
StoryTribe 当然还处于起步阶段,要完全实现这个愿景还需要更长的时间。话虽如此,我们在短短六个月内就已经达到了 10 万用户,而且没有任何营销成本,这表明用户已经看到了这个工具的价值。
StoryTribe 的独特之处在于其可定制性。用户可以控制细节,选择添加什么,放在哪里,还能调整大小、角度等。它还拥抱低保真和简单性的力量(简单的线条画,没有颜色),使其更易接近,更容易完成。这种有意的设计选择也帮助用户更多地关注想法和故事,而不是陷入最终的外观和感觉。(我们将在另一篇博客中深入探讨低保真的力量!)
StoryTribe 并不反对 AI。事实上, AI 功能已经在我们发展的计划中。我认为 StoryTribe 和 AI 将作为伙伴一起工作,实现一种更具互动性、对话式的人机视觉内容交流形式。
结论
AI 将继续进步,但作为人类,我们有一种内在的创造力驱动:我们天生想要创造自己独特的东西,与众不同,脱颖而出。这关乎拥有属于我们自己的东西,能反映我们自身身份的东西。所以,尽管 AI 作为一种工具存在,但最终应该是人类的创造力塑造最终成果。
点击访问 StoryTribe
评论(0)