
作者:Elie Bakouch、Leandro von Werra、Lewis Tunstall
原文链接:https://huggingface.co/blog/open-r1
什么是 DeepSeek-R1?
如果你曾经被数学难题困住,你一定知道 “多思考一会儿” 有多么重要。事实证明,大语言模型(LLM)在推理时如果使用更多计算资源,也能在完成数学、编程和逻辑等任务上表现得更好。
OpenAI 的 o1 模型展示了这一点:通过在推理过程中使用更多计算,它在推理任务上的表现显著提升。然而,OpenAI 的推理模型训练方法一直是个商业机密,直到上周,DeepSeek 发布了 DeepSeek-R1,并迅速在科技界引发轰动(甚至影响了股市)。
除了性能媲美甚至优于 o1 之外,DeepSeek-R1 的发布还附带了一份详细的技术报告,列出了其训练方法的关键步骤。其中最引人注目的创新之一是完全基于强化学习(RL),使基础语言模型能够自主学习推理能力,而无需任何人工监督。
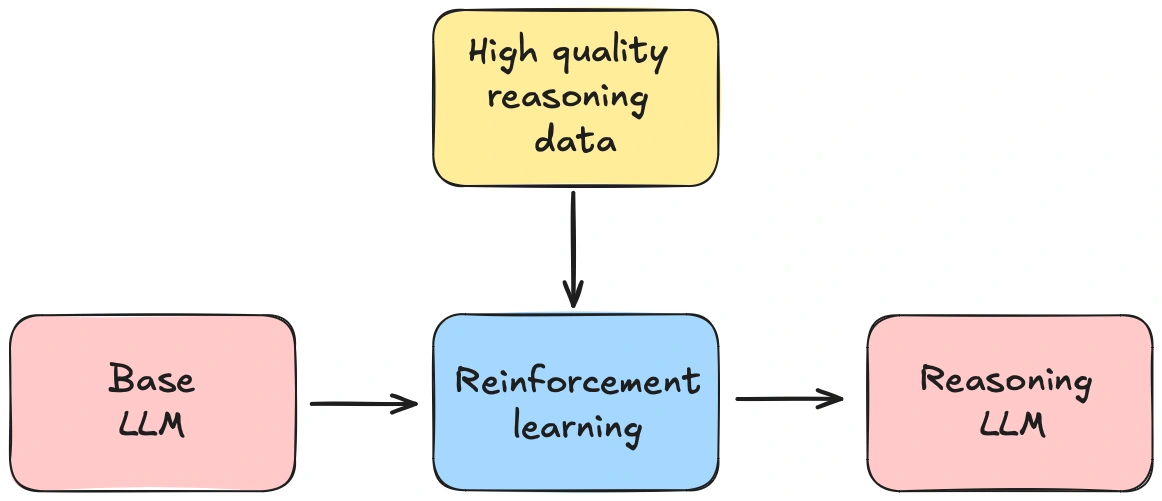
然而,DeepSeek-R1 的发布仍然留下了几个悬而未决的问题:
- 数据收集: 如何筛选出专门用于推理的高质量数据集?
- 模型训练: DeepSeek 没有公开训练代码,因此最佳的超参数设置仍然未知,不同规模的模型是否有不同的训练方法?
- 扩展规律: 在训练推理模型时,计算成本和数据量之间的权衡是什么?
这些问题促使我们启动 Open-R1 项目,旨在系统性地重建 DeepSeek-R1 的数据和训练流程,验证其研究成果,并推动开源推理模型的发展。
他们是如何做到的?
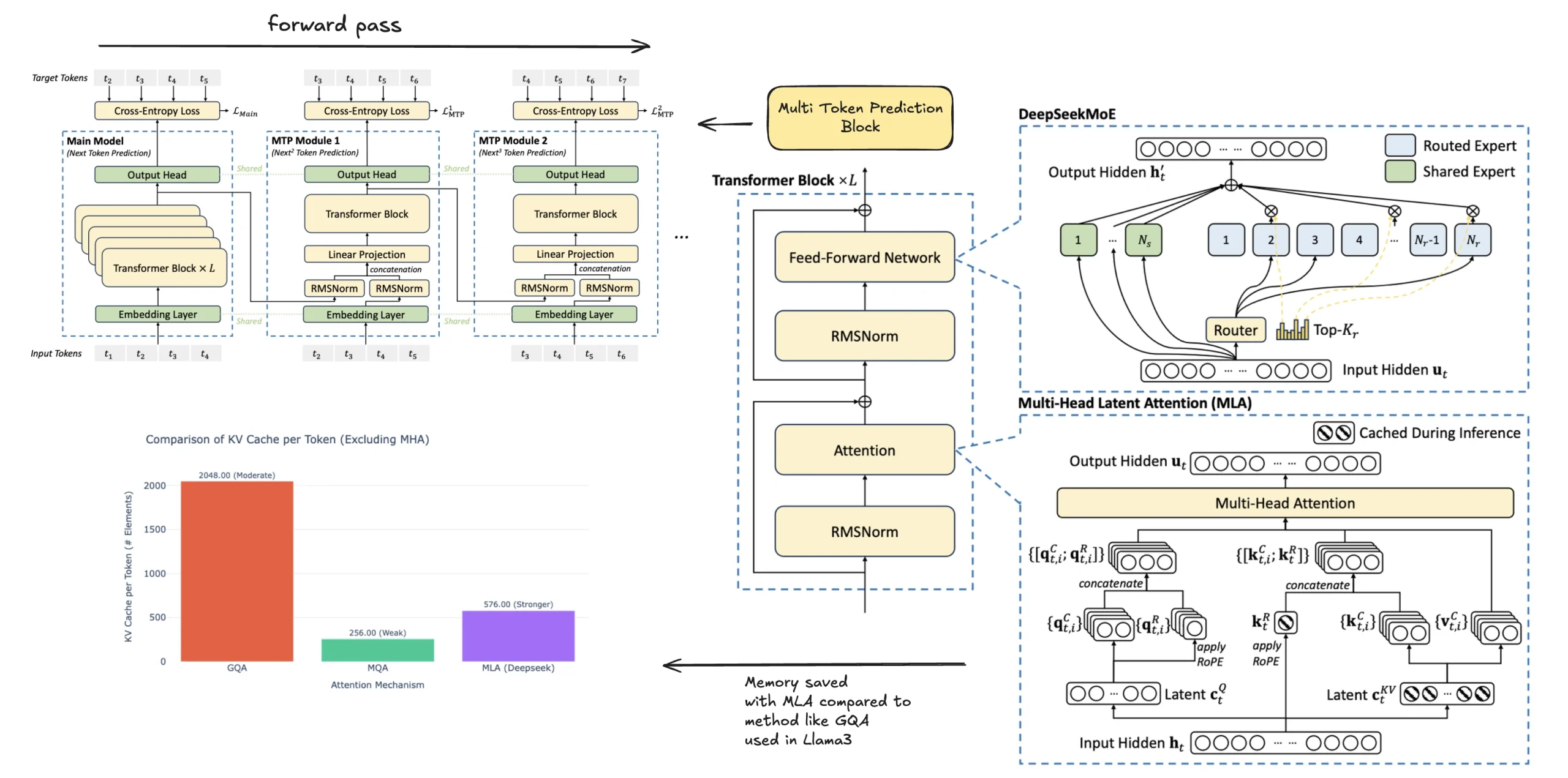
DeepSeek-R1 是基于 DeepSeek-V3 训练的推理模型。一个优秀的推理模型需要一个强大的基础模型,而 DeepSeek-V3 正是如此。
这个拥有 6710 亿参数的专家混合(MoE)模型,其性能可与 Claude Sonnet 3.5 和 GPT-4o 媲美,且得益于架构优化(如 多 token 预测(MTP) 和 多头潜在注意力(MLA)),训练成本仅为 550 万美元,极具成本效益。
DeepSeek-R1-Zero:完全基于强化学习的推理模型
DeepSeek-R1-Zero 没有使用任何人工标注数据,而是完全依赖强化学习(RL)训练。
- 训练方法: 使用群体相对策略优化(GRPO)提高强化学习效率。
- 训练目标: 通过简单的奖励机制让模型学会分步解题和自我验证答案。
问题: 虽然 R1-Zero 具备强大的推理能力,但其答案往往缺乏清晰度,不够易读。
DeepSeek-R1:强化学习 + 监督微调
为了解决这个问题,DeepSeek-R1 采用了"冷启动"(Cold Start)策略,先用高质量的人工标注数据进行微调,提升答案的可读性和一致性。
Open-R1:填补缺失的部分
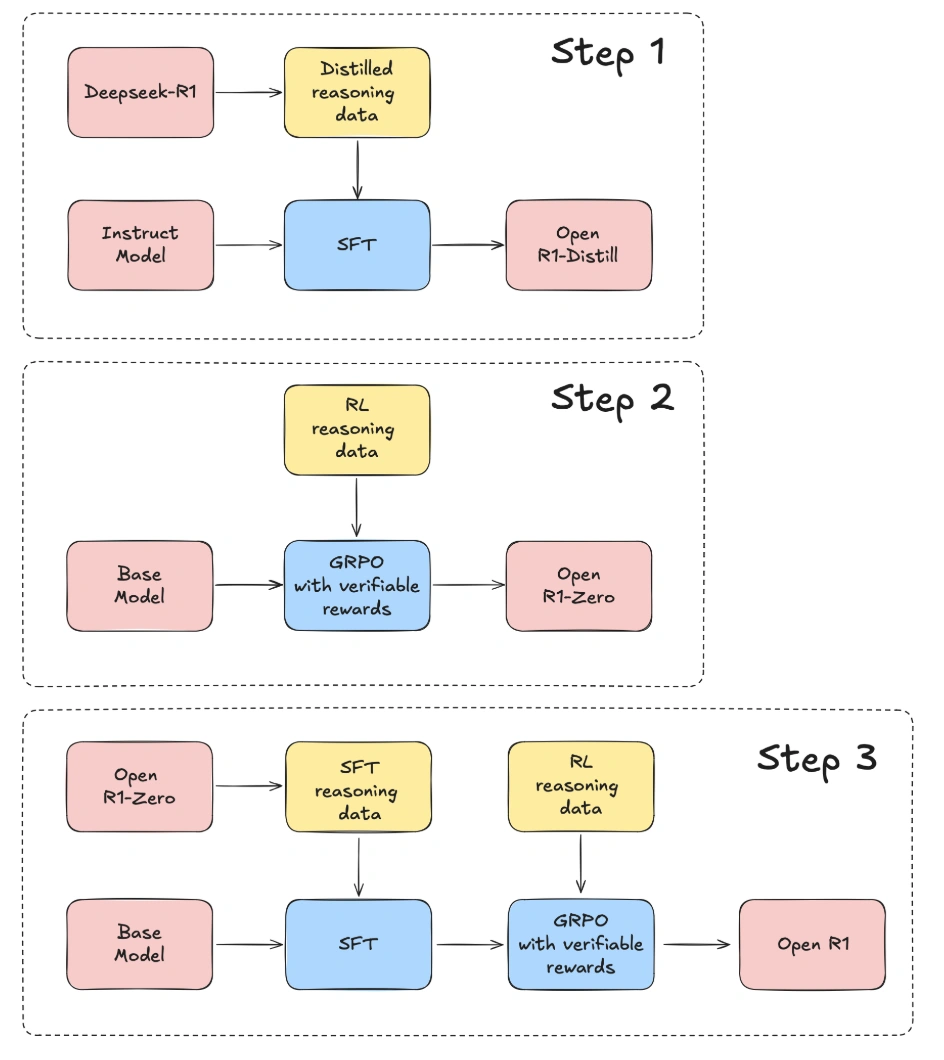
DeepSeek-R1 的发布极大地推动了推理模型的发展,但它并没有完全开源,虽然模型权重是公开的,但训练数据和代码并未开放。
我们的计划如下:
- 复现 R1-Distill 模型:从 DeepSeek-R1 提取高质量推理数据集。
- 复现 R1-Zero 的强化学习训练流程:构建全新的大规模数学、推理和编程数据集。
- 从基础模型 → 监督微调(SFT)→ 强化学习(RL),完成整个多阶段训练过程。
如何参与 Open-R1 项目?
这个项目不仅仅是对 DeepSeek-R1 的复现,更是一个开放的研究探索。
我们希望通过记录哪些方法有效,哪些无效,以及为什么,帮助大家避免不必要的计算浪费,提高研究效率。
想要参与?你可以:
- 贡献代码
- 在 Hugging Face 参与讨论
- 提供计算资源
- 帮助整理数据集
- 无论你的专业背景如何,我们都欢迎你的加入!让我们一起构建一个完全开源的推理模型
评论(0)